À quoi sert l’architecture ? Quels principes portent ma pratique de l’architecture ?
Manifeste d’architecture
En ce début d’année, j’ai fait l’exercice suivant : à quoi sert l’architecture ? quels principes portent ma pratique de l’architecture (ou du moins l’idéal que je m’en fais 😉) ?
L’architecture est un levier de valeur, de décision et de changement, au service de la compréhension et de l’évolution de l’organisation.
#1 L’architecture doit créer de la valeur
Une architecture qui n’aide pas l’organisation à produire de la valeur ne sert à rien. Elle est un moyen, jamais une fin.
#2 Comprendre avant de transformer
Avant de projeter une cible, il faut rendre le système d’information intelligible : clarifier les concepts, les responsabilités et les dépendances.
#3 Mettre les mots justes pour décider
Nommer les choses, poser des frontières et expliciter les choix permet de rendre les désaccords visibles et les décisions possibles.
#4 L’architecture est un outil de décision
Si l’architecture ne permet pas d’arbitrer, de prioriser et d’assumer des choix, elle devient un simple discours.
#5 Le réel prime sur les modes
Les technologies, méthodes et cibles idéales n’ont de valeur que si elles répondent aux contraintes réelles de l’organisation.
#6 Le changement est au cœur de la pratique
L’architecture agit sur des organisations vivantes. Elle doit accompagner le changement plutôt que l’imposer.
#7 Installer des pratiques durables
La valeur d’une mission d’architecture se mesure à ce qui continue de fonctionner après le départ de l’architecte.
#8 Refuser le bullshit est une responsabilité
L’honnêteté intellectuelle, la clarté et la transparence sont des conditions nécessaires à toute création de valeur.
Un système d’information mal cartographié perd sa capacité d’évolution. Mais au moment d’une refonte majeure, la machine s’enraye. On découvre alors que le SI, sans carte ni rangement, ressemble plus à un grenier encombré qu’à un patrimoine maîtrisé ! Comment faire ?
Un système d’information mal cartographié perd sa capacité d’évolution. On empile des briques, on multiplie les adhérences, et tout semble à peu près fonctionner tant qu’on ajoute simplement des fonctionnalités. Mais au moment d’une refonte majeure — migration cloud, rationalisation post-fusion, changement de socle technologique — la machine s’enraye. On découvre alors que le SI, sans carte ni rangement, ressemble plus à un grenier encombré qu’à un patrimoine maîtrisé.
👉 J’ai déjà écrit sur la cartographie du SI et sur les applications. Cet article est le chaînon suivant : comment donner une nomenclature à ce patrimoine.
Inventorier ne suffit pas
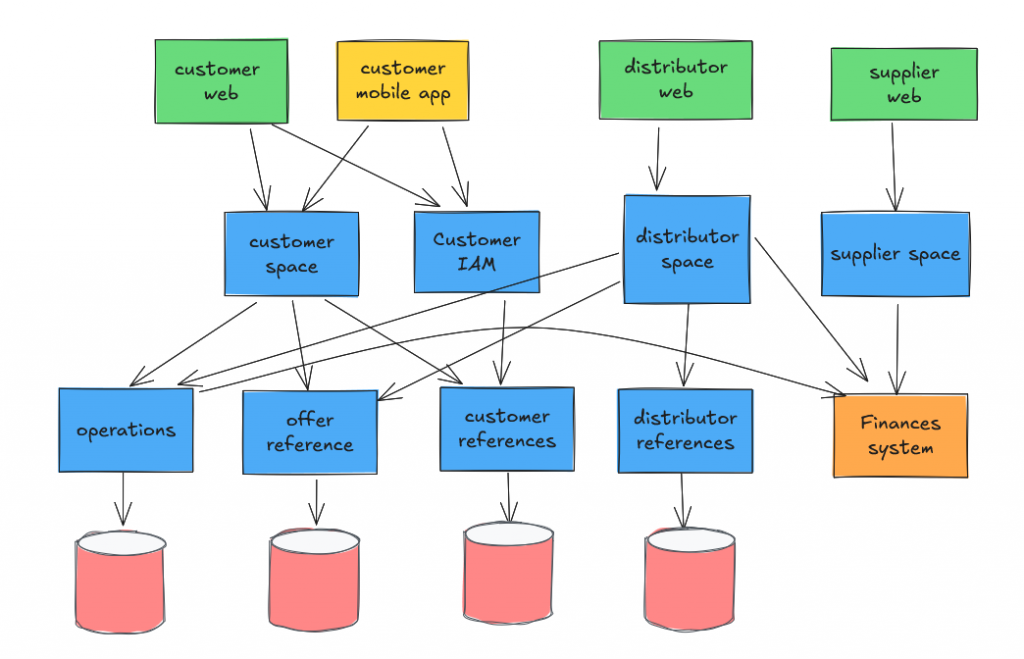
En général, quand je fais la découverte d’un système d’information, cela ressemble souvent au schéma ci-dessous en le multipliant par 10 ou plus. La complexité peut devenir vite redoutable !
La découverte du SI n’est pas forcément immédiate car elle nécessite d’avoir un inventaire applicatif ou de le faire s’il n’existe pas. Parfois, je trouve plusieurs inventaires applicatifs émis par plusieurs sources. Bien sûr, ils ne sont pas cohérents entre eux et la corrélation entre les items demande une certaine dose d’intuition !
Cependant, même si cette étape est nécessaire, elle ne suffit pas pour pouvoir tracer des trajectoires d’évolution du SI. Il faut pouvoir relier le SI à l’organisation afin que l’organisation comprenne comment se mobiliser pour étendre, changer et maintenir le SI. Cela paraît évident … et pourtant ! Il arrive souvent que des parties du SI soient à personne ou à plusieurs. Ces situations créent souvent des frictions.
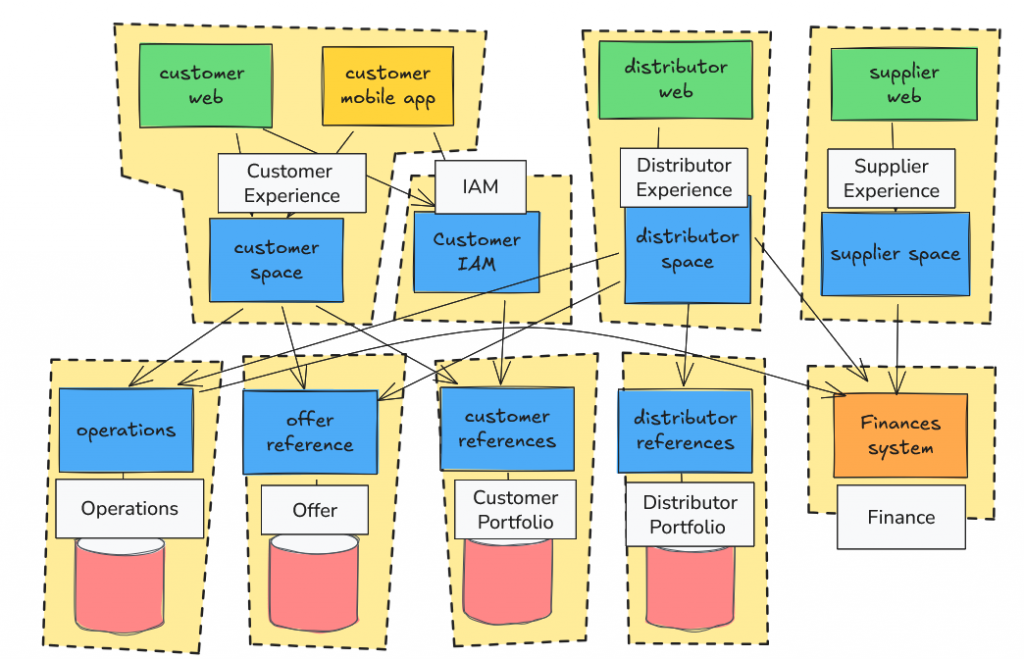
Nous avons besoin de créer un point de vue sur le patrimoine applicatif pour embarquer l’organisation. Afin de simplifier le schéma ci-dessous, nous pouvons regrouper les éléments en agrégat. Idéalement le regroupement a une signification pour le métier (nommé par des termes métier) et pour l’organisation (aligné sur la structure organisationnelle).
La représentation peut ensuite être simplifiée en ne conservant que les agrégats. On peut envisager de les ranger dans une Business Capabilité Map (BCM) ou dans une représentation visuelle type tableau des éléments périodique !
Les applications comme boîtes de rangement
Pour cartographier, il faut doc ranger. Et ce qu’on range dans le SI, ce sont des applications. L’application devient la boîte de référence : elle regroupe des fonctions, des données, des flux, et c’est sur elle que l’on raisonne pour décider si on conserve, remplace, modernise ou externalise.
Pourquoi ne pas utiliser l’unité de déploiement pour clé de rangement ? Avec le temps, l’unité de déploiement est devenue de plus en plus petite. On peut citer les architectures en micro-service ou en micro-frontend. Les SI deviennent ainsi découpés très finement. Il n’est pas rare de trouver plus de 2000 composants pour un SI d’une entreprise moyenne. Il est évident que travailler à cette échelle est très complexe et que l’alternative qui consiste à raisonner plutôt sur une centaine d’application est pragmatique.
Encore faut-il que cette boîte ait une identité stable. Sinon, on se retrouve avec une application qui change de nom selon les projets, qui se fond dans un programme puis ressurgit ailleurs, ou qui prend le nom du progiciel sur lequel elle est bâtie. Bref : impossible de suivre son histoire.
Le code applicatif : une identité stable
La réponse, c’est le code applicatif : une clé unique et durable, qui traverse tout le cycle de vie de l’application.
Le nom peut changer (souvent pour des raisons de communication), le code reste.
C’est ce code qui devient le label fédérateur : on le retrouve dans les workloads, les bases de données, les journaux, les rapports, les sauvegardes, les noms des machines, les flux réseau…
En systématisant la codification des assets de l’IT par rapport au code applicatif, on en tire des bénéfices à long terme :
Le cout de possession des applications se calcule comme la consolidation des couts des assets associés au code applicatif (couts directs) et la réimputation partielle des couts des assets communs (couts indirects).
Les assets orphelins sont un indice de ressources inutilisées ou un signalement d’un défaut organisationnel.
Relier applications et composants
Les développeurs, eux, travaillent sur des composants : des unités déployables. Pour que la nomenclature fonctionne, chaque composant doit porter le code de l’application à laquelle il appartient. C’est ce qui permet de relier la boîte (l’application) à ses briques techniques.
En faisant du composant un élément d’une application, il ne peut appartenir qu’à une seule application. Comme une application appartient à une seule équipe fonctionnelle et est opéré par une seule équipe IT, il n’y a pas d’ambiguïté sur le cadre de responsabilité du composant.
Donner du sens : typer les composants
Tous les composants ne sont pas égaux. Pour les ranger, il faut une typologie.
De mon expérience, trois critères suffisent :
Lieu de déploiement : chez le client, dans le SI interne ou chez un tiers.
État : service applicatif ou base de données (persistant ou non).
Mainteneur : interne ou tiers.
Avec ça, on obtient une règle de nommage simple :
[code applicatif]-[type composant]-[qualificatif]
Un exemple de types de composants courants :
Type de composant
Libellé
Lieu de déploiement
Etat
Mainteneur
app
Application mobile
client
sans
interne
web
Application Web
client
avec
interne
api
Service applicatif
SI
sans
interne
db
Base de données
SI
avec
interne
prg
Progiciel
SI
avec
tiers
saas
SaaS
Tiers
avec
tiers
Encadré pratique : exemple de nomenclature
Code applicatif
Type composant
Qualificatif
Nommage
paie
api
main
paie-api-main
paie
db
main
paie-db-main
paie
web
main
paie-web-main
paie
saas
studio
paie-saas-studio
finance
saas
sap
finance-saas-sap
Cette discipline rejoint les pratiques de l’APM (Application Portfolio Management) décrites par MEGA, LeanIX, Ardoq : avoir une nomenclature standardisée, claire et unique est ce qui permet de comparer les applications, d’identifier les doublons, et surtout de prendre des décisions stratégiques.
APM et Product Management : un rendez-vous manqué ?
L’APM existe depuis plus d’une décennie. Il propose un cadre clair pour inventorier, évaluer et rationaliser le portefeuille applicatif. Sur le papier, l’APM devrait être incontournable — or il reste souvent cantonné aux directions architecture ou urbanisme, perçu comme une démarche “d’ingénieurs de la cartographie”.
Pourquoi ? Parce que, pendant ce temps, l’agilité et le product management ont changé le vocabulaire et les priorités. Là où l’APM range et classifie, le product management valorise, priorise et fait évoluer. On a d’un côté une logique patrimoniale et transverse, de l’autre une logique opérationnelle et orientée produit.
👉 Le paradoxe, c’est qu’il s’agit en réalité de deux faces de la même pièce : le product management gère la valeur courante, l’APM gère la soutenabilité dans le temps.
Deux flux orthogonaux : projets et patrimoine
On peut représenter le SI comme traversé par deux flux :
Les projets : financés, pilotés, visibles. Ils incarnent “l’argent bien dépensé”, car ils créent des nouveautés.
Le patrimoine : maintenance, mises à jour, obsolescence. Il incarne “la dépense forcée”, qu’on subit plus qu’on ne la choisit.
Historiquement, l’organisation a séparé les deux, créant une fracture :
le projet est glorifié,
le patrimoine est toléré.
L’agilité a tenté de dépasser cette contradiction en fusionnant projet et patrimoine dans la même unité : le produit. Le product management va encore plus loin en donnant une équipe, un budget et une feuille de route à chaque produit.
La limite : les programmes transverses
Mais la fusion n’est pas toujours possible. Lorsqu’on conduit un programme transverse (par exemple : rationaliser tout le domaine finance, ou remplacer un progiciel de référence), on sort du périmètre d’un produit. On touche à des morceaux multiples du patrimoine, qui n’ont pas été pensés pour évoluer ensemble.
Et c’est là que l’APM redevient critique :
il donne la vision transverse,
il révèle les doublons et les adhérences,
il permet d’arbitrer rationnellement au-delà du périmètre produit.
En ce sens, l’APM ne s’oppose pas au product management : il l’encadre et le complète.
Conclusion : ranger pour évoluer
Un patrimoine applicatif, c’est comme une bibliothèque. Tant que les livres n’ont pas de code et qu’ils ne sont pas rangés dans des catégories claires, on peut toujours lire, mais on ne retrouve rien et on ne remplace rien sans douleur.
Avec un code applicatif unique et une nomenclature simple, on passe d’un grenier en désordre à une bibliothèque organisée. Et surtout, on redonne au SI ce qui lui manque le plus souvent : sa capacité d’évolution.
Pour éviter le quick & dirty systématique, la définition et la mise en oeuvre des exigences techniques peuvent aider.
La définition des exigences techniques et leur mise en œuvre effective font partie des pratiques les plus difficiles sur les projets informatiques, toutefois nécessaires. Que se passe-t-il quand elles ne sont pas réalisées ? Face à un métier pressé, la solution rapide, dite quick and dirty1, est une option attrayante. Et quand elle est déployée, il est difficile d’avoir l’accord du métier pour la refaire en plus solide. Après tout, le métier a eu ce qu’il veut et ne voit pas, de prime abord, le bénéfice à ce refactoring. La maintenance du code est le problème des informaticiens ! Face à cet aléa moral2, la pratique des exigences techniques peut apporter une réponse.
Les exigences techniques ne sont pas les exigences de l’IT
Les exigences techniques (ou exigences non-fonctionnelles) sont aussi nécessaires que les exigences fonctionnelles pour permettre à l’application (ou au produit) de répondre aux attentes. Une application, qui n’adresserait que des exigences fonctionnelles, serait certes utile, mais pas utilisable et donc pas utilisée (d’où quelques frustrations !). Par exemple, un utilisateur face à une interface lente (problème de performance) ou confronté à des informations peu fiables (manque d’intégrité) ou encore échangeant avec un système non sécurisé (divulgation d’information) finira par trouver d’autres possibilités plus acceptables avec son mode opératoire. À la différence des exigences fonctionnelles, elles ont une portée globale et leur validation passe par d’autres mécanismes que la recette fonctionnelle (tests de performance, tests de sécurité, tests de robustesse, qualimétrie, …).
Les exigences techniques sont désignées de la sorte, car leur validation passe par des moyens techniques et non parce qu’elles sont à l’origine des acteurs IT !
Ce malentendu, probablement dû à un nommage malheureux, peut faire croire aux acteurs Métier qu’ils ne sont pas concernés (ou qu’ils peuvent se sentir légitimes à ne pas les prendre en considération !).
L’acronyme FURPS+ permet de se rappeler une classification des exigences dans leur ensemble. Dans cette méthodologie, le point de départ est un ensemble de questions qui s’adressent au métier pour l’aider à qualifier les exigences. Toutes ces questions sont intéressantes pour le métier.
Fonctionnalité : Que veut-faire le métier ? Les besoins liés à la sécurité sont aussi inclus sous ce terme.
Facilité d’Utilisation : Dans quelle mesure le produit est-il efficace du point de vue de la personne qui s’en sert ?
Résilience : Quel est le temps d’arrêt maximal acceptable pour le système ? Comment redémarrer le service ?
Performance : Quelle doit être la rapidité du système ? Quel est le temps de réponse maximal ? Quel est le débit ?
Supportabilité : Est-il testable, extensible, réparable, installable et configurable ? Peut-il être supervisé ?
Le ‘+’ final désigne des considérations IT qui peuvent ne pas intéresser directement le métier telles les contraintes de conception, d’implémentation ou encore de déploiement. Toutefois, leur mise en œuvre affecte la qualité du produit et concerne in fine le métier.
Piloter la complexité du SI
Les architectes sont garants de la bonne santé du système d’information, mais aussi de la proportionnalité des moyens alloués par rapport aux objectifs attendus. Cela se traduit par la maitrise de la complexité du SI dans un cadre spatio-temporel.
Sur un plan spatial, la complexité devrait être concentrée dans les zones du SI où elle apporte de la valeur. La complexité n’est jamais gratuite ! Le framework Cynefin est une bonne méthode tactique pour adapter la réponse au problème. Pour les situations simples, des solutions simples… et pour des situations complexes, des approches émergentes ! Ce principe semble marquer au coin du bon sens. Pourtant, la tentation des solutions « Et ce serait cool si … » est très forte pour des technophiles et autres adorateurs de la nouveauté. Malheureusement, quand l’effet « cool » s’essouffle, la maintenance devient un problème épineux et les adorateurs de la première heure peuvent être déjà partis… À un niveau plus stratégique, on peut s’appuyer sur le Core Domain Chart est pour prioriser les domaines où insérer de la complexité peut être payant, par exemple pour se différencier (en bien !).
Abordons maintenant la dimension temporelle. La complexité a la fâcheuse propriété à augmenter dans le temps. Cela peut se faire de façon passive avec le phénomène d’entropie, obtenu par un cumul de changements dans le code, dégradant la conception du système, mais aussi de façon active quand l’application répond à de sollicitations de plus en plus grandes. Paradoxalement, une application qui connait une réussite dans son usage peut se voir injecter une dose de complexité qui pourra finir par la tuer, victime de son succès en quelque sorte !
Quand la complexité devient trop importante, l’application n’est plus maintenable et évolutive, ce qui implique sa fin de vie à plus ou moins brève échéance. Les projets en Quick and Dirty 3 arrivent plus vite que les autres à ce stade fatidique.
L’idéal est de réaliser, maintenir et opérer des applications qui atteignent les exigences tout en minimisant la complexité le plus bas possible.
Si les exigences ne sont pas posées, alors la complexité peut ne pas être adaptée au besoin (et c’est souvent le cas, en pratique) que ce soit par insuffisance (une solution simpliste qui ne répond pas au besoin) ou par excès (un « marteau pour écraser une mouche », aussi connu comme l’anti-pattern Marteau doré)
Base du contrat de confiance entre métier et SI
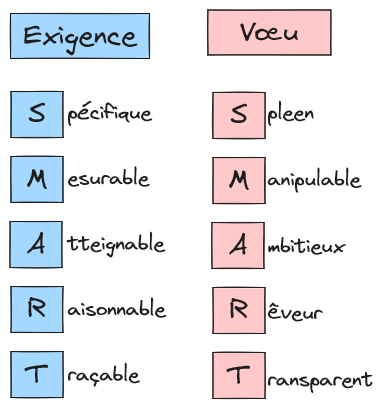
L’exigence peut servir à écrire des articles dans le contrat de confiance entre métier et IT, à condition d’être SMART.
Pour se rappeler ces bonnes caractéristiques, l’acronyme SMART est un bon moyen mnémotechnique.
L’exigence est Spécifique pour ne pas être qu’un souhait.
L’exigence est Mesurable pour ne pas être qu’une promesse en l’air.
L’exigence est Atteignable pour être un engagement sincère.
L’exigence est Raisonnable pour avoir du sens.
L’exigence est Traçable pour être une propriété effective de l’application.
« Faire ce qu’on fit et faire ce qu’on dit » est généralement une bonne pratique pour instaurer une bonne relation de confiance ! L’exigence permet de poser et partager un attendu et de se donner les moyens de l’atteindre effectivement.
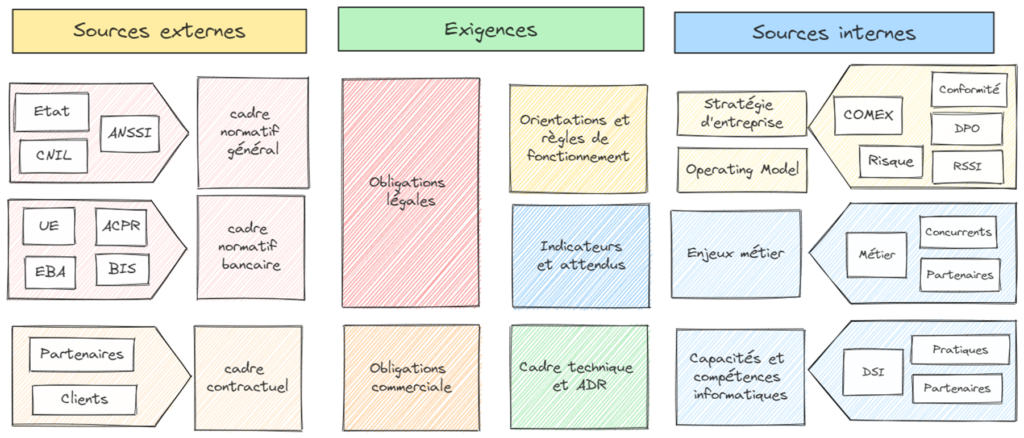
Tout le monde a des attentes !
Toutes les parties prenantes ont des attentes par rapport au SI. Elles peuvent être en dehors du cadre de l’organisation (administrations, partenaires, clients) ou à l’intérieur (direction générale, contrôle interne, direction métier, direction informatique, etc).
Les contributeurs des exigences
Ces attentes peuvent être déclinées en exigences. Entre l’attente et l’exigence, l’écart sera plus ou moins important en fonction du caractère contraignant de l’attente (par exemple, une disposition règlementaire) et de la marge d’interprétation. L’écart pourra être ajusté suite à une négociation.
Il est recommandé de collecter ces attentes le plus tôt possible et non de les découvrir à la fin de l’itération. Une attente pourra être suffisamment contraignante pour remettre en cause une partie de l’implémentation et sans doute le calendrier !
À l’inverse, il ne faut pas être plus royaliste que le roi. Pour les premières itérations, des exigences faibles pourront être acceptables, sachant que les exigences seront redéfinies pour les itérations finales dans des formes plus élevées. C’est un des principes dela Continuous Architecture et de l’ Architecture Runaway.
Comment calibrer les exigences ?
Si l’objet des exigences techniques est bien connue (FURPS+, cela vous parle ? 😉), en revanche le calibrage est plus difficile.
Prenons une exigence portant sur la vitesse d’affichage d’un écran. Comment définir la valeur à atteindre en cible ? Il faut à la fois tenir compte du fonctionnement de l’attention humaine (moins d’une seconde pour garder la fluidité dans l’interaction), des attendus des utilisateurs au travers de leur expérience digitale, que ce soit dans un cadre professionnel ou personnel (les services des GAFAM sont rapides !), et des moyens techniques communément atteignables par une organisation classiques. Une façon d’apporter une réponse est de se comparer au marché. Voulons-nous que l’application se situe dans le 1% des meilleurs, le premier décile, la première moitié ou peu importe ? C’est l’idée des Core Web Vitals, prendre en compte les statistiques de HTTP Archive et construire des cibles par rapport à ce que l’on fait. Une exigence construite sur ce principe a la particularité de varier dans le temps, car chaque année, le niveau peut monter (et même baisser, c’est possible).
Pour d’autres exigences plus normatives comme la sécurité ou l’accessibilité, il existe des normes avec des niveaux de conformité plus ou moins élevées à aller chercher (RGAA pour l’accessibilité, OWASP pour la sécurité, par exemple).
Le compétiteur ou la référence du marché peut aussi donner des idées. La concurrence a du bon ! C’est souvent un bon argument pour ajuster l’exigence à un niveau à la fois performant et raisonnable.
Et si malgré tout, on ne trouve pas toujours pas d’inspiration, on pourra se référer sur les référentiels d’exigences classiques comme DICT. Si les niveaux élevés de DICT sont atteignables par les moyens techniques mis à dispositions par les hyperscalers, les limites posées par la capacité financière et par l’organisation de l’exploitation restent toujours à adresser.
Passer du besoin à l’exigence
Les attentes peuvent être, au départ, implicites ou alors abstraites. Cela peut conduire à plusieurs écueils :
Le demandeur formule une exigence absolue (par exemple, une demande d’une disponibilité à 100%). La motivation peut être une aversion au risque (et un transfert de responsabilité à l’IT). Le demandeur peut aussi ne pas comprendre en quoi cette question le concerne alors que la qualité du résultat dépend du niveau d’exigence.
Le demandeur renvoie la question à l’IT en demandant ce qu’elle peut fournir au mieux.
Le demandeur n’a qu’une seule exigence, qu’il n’y a pas de problème ! 😒
Fournir un catalogue de niveau de service sur lequel l’IT peut s’engager est une bonne base de discussion. Ce catalogue consiste en une liste d’exigences SMART organisées par niveau de service.
Cela permet de ne pas partir d’une feuille blanche et de disposer d’un format synthétique pour faciliter les échanges. De plus, plus que 90% des applications rentrent certainement dans des niveaux standards. On a donc un gain de temps significatif dans la qualification des exigences. Cela permet de se concentrer sur les quelques applications critiques qui vont nécessiter des moyens particuliers pour atteindre des niveaux de service très élevés.
Disposer d’un niveau de service minimal permet de définir dans tous les cas un engagement explicite, y compris unilatéralement. Et si ce niveau ne correspond aux attentes effectives lors d’incident, alors il est toujours possible de requalifier le niveau de service et de lancer un chantier de remédiation.
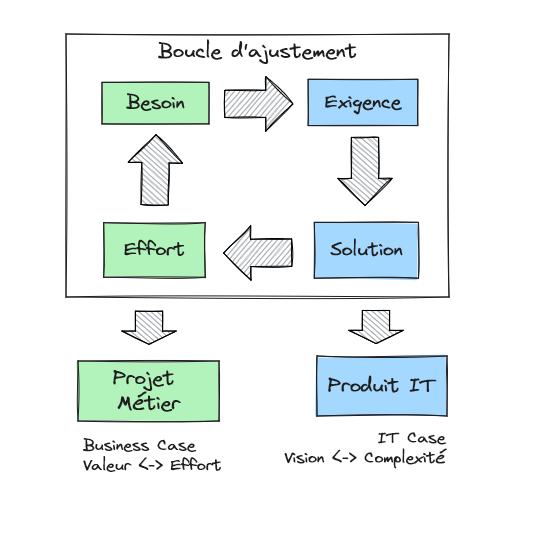
Passer de l’exigence au business case
À ce stade, nous disposons d’exigences SMART. Elles sont suffisamment claires pour pouvoir évaluer les conséquences concrètes sur la construction et l’exploitation des applications. Nous disposons de bases pour estimer l’effort de fabrication, mais aussi le cout de fonctionnement.
Les exigences peuvent s’avérer trop onéreuses au regard de la valeur attendue ou alors trop complexes à mener au vu des ressources de l’organisation. À ce moment, le demandeur peut revoir le besoin afin d’améliorer le business case de la solution ou sécuriser sa mise en œuvre.
L’ajustement des exigences pour adapter l’effort à la valeur attendue permet de mettre le projet sur des bases équilibrées : le bon niveau d’effort pour le bon résultat attendu. Quand le métier et l’IT sortent tous les deux gagnants dans la réalisation du business case et dans la mise en place du produit, c’est une situation plutôt satisfaisante ! Pour cela, même si les exigences demandent de prendre un chemin parfois difficile, la récompense à l’arrivée en vaut la peine !