
Le cache, mal aimé et pourtant indispensable
La réputation du cache de données dans le monde de l’informatique est bien curieuse. Son usage est largement répandu. Pour autant, le cache apparaît comme une complication ou même un risque avec la corruption de cache. Comme toute technique puissante, elle peut avoir des conséquences désastreuses par un mauvais emploi. Il est temps de faire le plaidoyer du cache et lui redonner sa place légitime !
La sortie rapide de la salle d’attente
Le cache est employé à différente échelle dans les systèmes informatiques, du microprocesseur jusqu’au réseau Internet. Le cache est un levier de performance très puissant, en substituant une opération lente par un accès rapide en mémoire. Les applications passent l’essentiel de leur temps dans une sorte de salle d’attente. Le cache est, en quelque sorte, une sortie rapide dans cette salle d’attente ! Réduire le temps de présence des applications dans la salle d’attente est un moyen particulièrement efficace pour accélérer leur fonctionnement, juste après celui de la mise à disposition de ressources suffisantes aux applications (traitement, mémoire, réseau, stockage).

La déraisonnable efficacité du cache
Pour que le cache soit effectif, il faut non seulement qu’il dispose d’une alternative rapide aux opérations réelles, mais aussi qu’il puisse effectuer cette substitution dans un « bon nombre » de cas. La fréquence de substitution applicable s’appelle le cache hit rate. Il n’y a rien d’évident à ce que le taux de hit soit élevé, de l’ordre de 80%, et indépendant de la taille relative du cache par rapport au volume des données opérationnelles. Le cache s’appuie sur une heuristique qui se vérifie dans les cas courants : la localité temporelle et spatiale. Généralement, un utilisateur travaille sur une zone locale de l’espace des données (un agrégat fonctionnel, par exemple) dans un intervalle de temps délimité. Ce mode opératoire conduit naturellement le cache à avoir un taux de hit élevé, même sans préchauffage de cache.
À la rescousse de l’expérience utilisateur
Le cache améliore le ressenti utilisateur même s’il ne suffit pas à lui seul à atteindre l’objectif de temps de réponse. Par exemple, le taux de hit peut atteindre 80% quand on vise dans 95% des cas à rester sous la barre des 3 secondes de temps de réponse. Pour autant, le ressenti utilisateur sera meilleur avec une réponse rapide dans 80% des cas. C’est sur ce principe qu’est calculé l’indice Apdex qui évalue le ressenti des clients finaux quant à la performance.
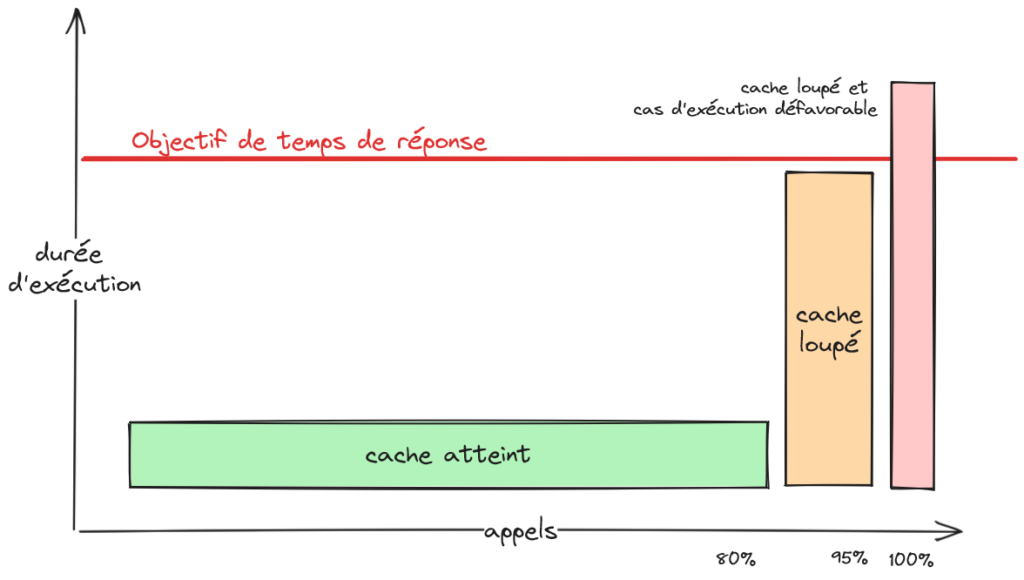
À l’inverse, une application trop lente devient inutilisable et les utilisateurs finaux expriment alors leur rejet. Cette lenteur est souvent causée par des opérations d’entrée-sortie (I/O) trop nombreuses ou trop lentes (voire les deux !). Le cache est particulièrement efficace dans ce genre de situation, en remplaçant ces opérations lentes par des équivalents nettement plus rapides. La mise en place et la configuration de cache ont aussi le bon gout de ne pas trop altérer le code et de réduire les risques de régression. C’est donc une méthode efficace et rapide de résolution de problème de performance, quand elle est applicable (ce qui n’est malheureusement pas toujours le cas 🙁 ). Elle m’a permis de redresser des projets, à plusieurs reprises dans ma carrière. Au passage, la performance apparaît comme une des rares caractéristiques d’architecture qui soit perceptible dans l’expérience des utilisateurs finaux ! C’est un élément tangible de ce que peut apporter la pratique d’architecture aux projets d’informatique.
Protection contre la charge
Le cache est aussi un réducteur de la consommation des ressources. Il évite de réaliser sans cesse des opérations qui produisent le même résultat. Outre le gain d’efficience évident, le cache évite la saturation des ressources qui va provoquer une dérive du système. Le cache peut ainsi être vu comme une mesure de protection contre un nombre de sollicitations trop important, qu’il soit intentionnel (par exemple, une attaque DDoS) ou non. J’avais eu le cas d’un site Internet saturé à cause du traitement des sollicitations des agrégateurs RSS qui prenaient plus de 90% de la capacité de traitement. La mise en cache des flux RSS a résolu la situation. Dans cette veine, on peut citer la conception Jamstack qui permet de remplacer un site Web dynamique par un site statique facile à mettre en cache et aussi à distribuer, autour du monde.
Le cache peut aussi nous faire faire des économies. La mémoire coute moins cher que le CPU. Il vaut donc mieux mettre un résultat stable en mémoire que le recalculer. Avec une allocation de 4 Go par CPU sur les gabarits habituels de machine, la mémoire est de facto très abondante.
Le problème de l’invalidation du cache
There are only two hard things in Computer Science: cache invalidation and naming things.
Phil Karlton
Mais, alors, pourquoi avec toutes ces qualités, le cache n’a-t-il pas bonne presse ? Le problème est que le cache peut être corrompu, c’est-à-dire contenir des données qui ne sont plus à jour, donc fausses. Les utilisateurs peuvent alors être induits en erreur et prendre de mauvaises décisions. Enlever les données dépassées du cache (ou les remplacer par des données fraiches), c’est ce que l’on appelle invalider le cache. Il n’existe pas, dans le cas général, de méthode efficace, correcte et performante pour invalider le cache, une méthode qui à la fois donne un taux de hit du cache élevé (efficace), évite l’utilisation des données dépassées (correcte) et n’introduit pas de blocage (performante). La raison profonde est qu’il est difficile d’établir un consensus entre la source de vérité et le cache, sans qu’à un moment, il n’y ait une suspension pour la synchronisation. On peut faire une analogie avec le problème des généraux byzantins, que l’on rencontre dans le monde des blockchains.
La résolution de l’invalidation par la maitrise du point de vérité
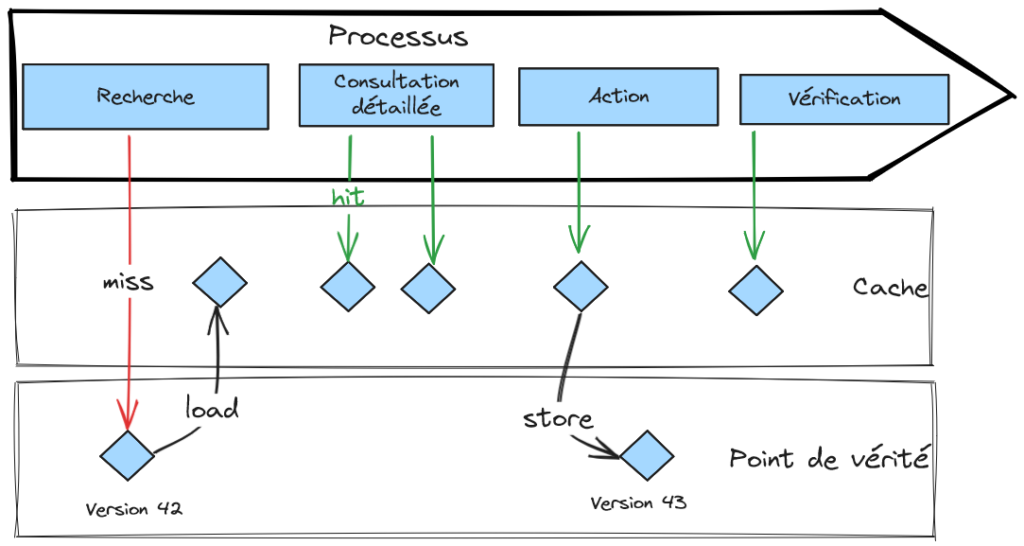
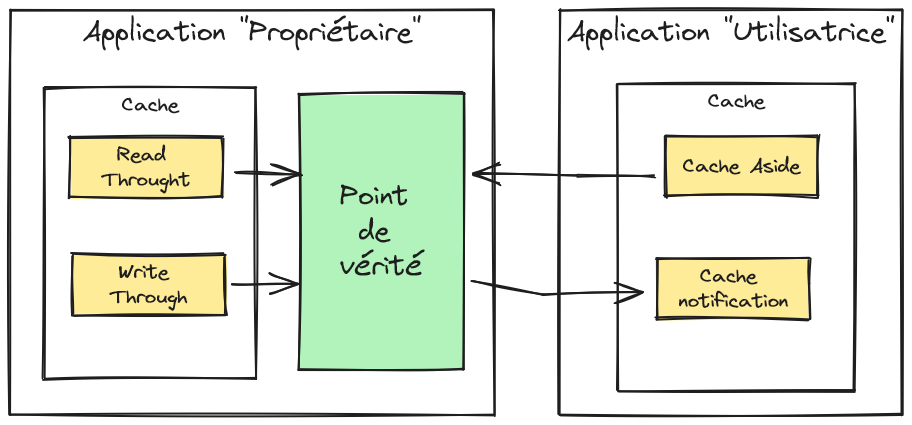
Le cache peut être réputé non corrompu dans plusieurs cas particuliers, en établissant une acceptation de la fraîcheur du cache sous un ensemble de condition. Le cas le plus favorable est quand l’application qui porte le cache dispose aussi du point de vérité de façon unique. Elle peut alors garantir que le cache est mis à jour « en même temps » que le point de vérité. Cela correspond aux stratégies de cache, Read Through et Write Through. Quand l’application est déployée en plusieurs instances (ce qui est maintenant la norme), ce cas demeure applicable si l’implémentation du cache supporte la distribution et fournit une sémantique garantissant l’atomicité des opérations sur le cache. Le deuxième cas, un peu moins favorable, est quand l’application qui a le cache reçoit des notifications de la source de vérité. L’application peut considérer le cache comme à jour au délai près de la notification. Évidemment, le délai de notification n’est pas borné et peut dériver en cas de forte charge. Il faudra prendre en considération cette situation dégradée. Enfin, l’application peut accepter d’utiliser des données dépassées pour les opérations en lecture, mais toujours justes lors des opérations d’écriture (on vérifie alors que le cache est bien en accord avec la source de vérité, il s’agit de méthode de verrou optimiste).
La résolution de l’invalidation par le cycle de vie de la donnée
Il existe une façon plus puissante d’avoir un cache à jour qui dépend du cycle de vie de la donnée. La donnée immuable est la donnée idéale pour un cache ! Malheureusement, rien n’est vraiment immuable dans notre monde. Le changement est la seule constante dans la vie ! En revanche, on trouve facilement des données stables, des données dont l’état change dans une échelle de temps sensiblement plus grande que la durée des processus fonctionnels. Par exemple, nous avons un produit en vente. Son prix est révisé tous les mois et la durée du tunnel de vente est rapide, moins d’une heure. Dans ce contexte, le prix du produit est une donnée stable. On peut gérer les données stables avec la notion de durée de vie (Time To Live) qui permet de faire une invalidation dans un mode distribué. Si une donnée est versionnable, c’est-à-dire que la version permet de fixer son état de la donnée, alors les versions de la donnée peuvent être mises en cache sans risque de corruption. Enfin, il y a un cas réellement antagoniste à la mise en cache : ce sont les séries chronologiques et les flux de données (data stream).

Cache By Design
Et, si le cache était prévu dès la conception ? On pourrait alors espérer concilier les avantages décrits précédemment tout en mitigeant le risque de données dépassées (Stale data). Il s’agit donc essentiellement de privilégier la manipulation de données immuables.
La première approche qui vient en tête est l’Event Sourcing : le changement d’état est défini des événements et l’état est la résultante de la série des événements. Les événements sont des données stables, faciles à propager et à copier. L’état est éventuellement consistant. La cohérence de l’information est assurée à un écart correspondant au délai de propagation global et au taux de perte de transmission des messages. L’état d’une application dépend de la somme des événements reçus et sera altéré par des événements perdus ou arrivés trop tard. Dit comme cela, le degré de confiance dans l’exactitude de l’état peut être faible. Pour autant, l’application est capable de produire un état dans des conditions dégradées dans cette configuration alors qu’elle ne le pourrait pas dans une conception strictement synchrone. Pour revenir à notre sujet, les événements sont de bons candidats à mettre en cache et le calcul de l’état peut se faire en mémoire.
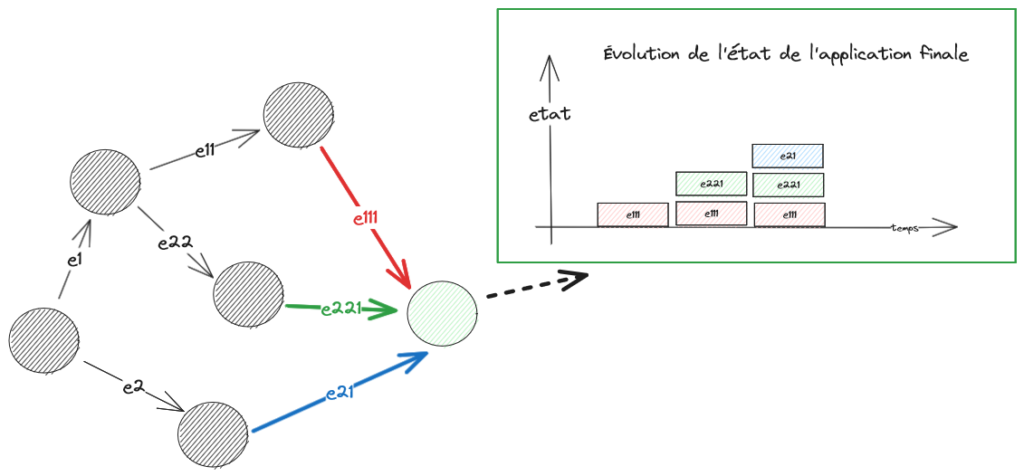
Sur le schéma ci-dessus, le graphe de propagation des événements a la qualité d’être acyclique, ce qui permet de garantir la stabilité de l’état à terme. En présence de cycle, la définition de l’état stable pour l’ensemble du système est plus problématique.
Une autre approche, moins classique, consiste à tracer les versions des objets et aussi les versions des objets antécédents, un peu à la façon d’une Horloge de Lamport. Les versions des objets sont mises en cache comme elles sont immuables. Il est également possible de détecter quand nous manipulons une version d’objet alors qu’une plus récente est disponible et de pouvoir traiter ces cas de corruption de cache. Comment ? L’Horloge de Lamport va nous aider.
Prenons le cas ci-dessous. Nous avons des émetteurs de versions d’objets. À chaque émission, la version est incrémentée. Également, dans les transmissions, nous communiquons la version de l’objet, mais aussi celle de ses antécédents. Par exemple, B émet un message vers C indiquant qu’il envoie la version 2 de B, construite avec la version 1 de A. Si le message de E arrive avant C ou D, un risque de corruption se présente, car la version 2 de A va être ingérée avant la version 1. On peut le voir autrement, F va récupérer des versions de C et D en retard avec la version de A qu’il a reçu. De façon générale, on a un risque d’incohérence globale. Le cas idéal est quand les versions des objets à chaque point du système ne font que croitre (ce sont des fonctions monotoniques).
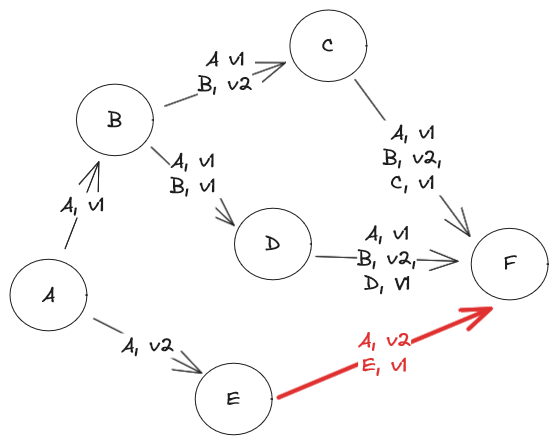
La détection pourrait être réalisée à chaud, avec un différé correspondant au délai de propagation des messages estimé, comme dans le cas de l’Event Sourcing. Mais, on peut aussi opter pour une approche à froid : la détection est alors plus efficiente et a un degré de confiance plus élevée. L’approche à froid est séduisante, car on peut s’appuyer sur cette heuristique : la plupart des corruptions de cache n’ont pas de conséquence. En effet, la donnée peut être mise à jour un plus tard et une réparation se fait souvent lors de cette mise à jour. Ou encore la donnée est conservée à titre de mémoire et n’est pas ensuite exploitée. Rares sont les cas où une mauvaise décision est prise alors que la donnée n’est pas à jour et ne peut être compensée. Un corollaire à cette heuristique est la mauvaise qualité des données dans le système d’information qui malgré tout fonctionne.
Effectivement, les approches de Cache By Design sont plus avancées que celles rencontrées habituellement. Pour autant, elles peuvent aller chercher la performance supplémentaire requis pour certains besoins. En architecture, la réponse est souvent : « ça dépend … » 🙂