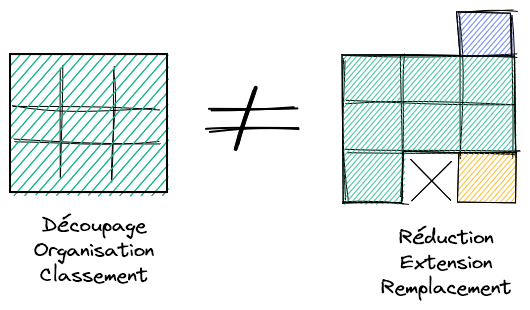À quoi sert l’architecture ? Quels principes portent ma pratique de l’architecture ?
Manifeste d’architecture
En ce début d’année, j’ai fait l’exercice suivant : à quoi sert l’architecture ? quels principes portent ma pratique de l’architecture (ou du moins l’idéal que je m’en fais 😉) ?
L’architecture est un levier de valeur, de décision et de changement, au service de la compréhension et de l’évolution de l’organisation.
#1 L’architecture doit créer de la valeur
Une architecture qui n’aide pas l’organisation à produire de la valeur ne sert à rien. Elle est un moyen, jamais une fin.
#2 Comprendre avant de transformer
Avant de projeter une cible, il faut rendre le système d’information intelligible : clarifier les concepts, les responsabilités et les dépendances.
#3 Mettre les mots justes pour décider
Nommer les choses, poser des frontières et expliciter les choix permet de rendre les désaccords visibles et les décisions possibles.
#4 L’architecture est un outil de décision
Si l’architecture ne permet pas d’arbitrer, de prioriser et d’assumer des choix, elle devient un simple discours.
#5 Le réel prime sur les modes
Les technologies, méthodes et cibles idéales n’ont de valeur que si elles répondent aux contraintes réelles de l’organisation.
#6 Le changement est au cœur de la pratique
L’architecture agit sur des organisations vivantes. Elle doit accompagner le changement plutôt que l’imposer.
#7 Installer des pratiques durables
La valeur d’une mission d’architecture se mesure à ce qui continue de fonctionner après le départ de l’architecte.
#8 Refuser le bullshit est une responsabilité
L’honnêteté intellectuelle, la clarté et la transparence sont des conditions nécessaires à toute création de valeur.
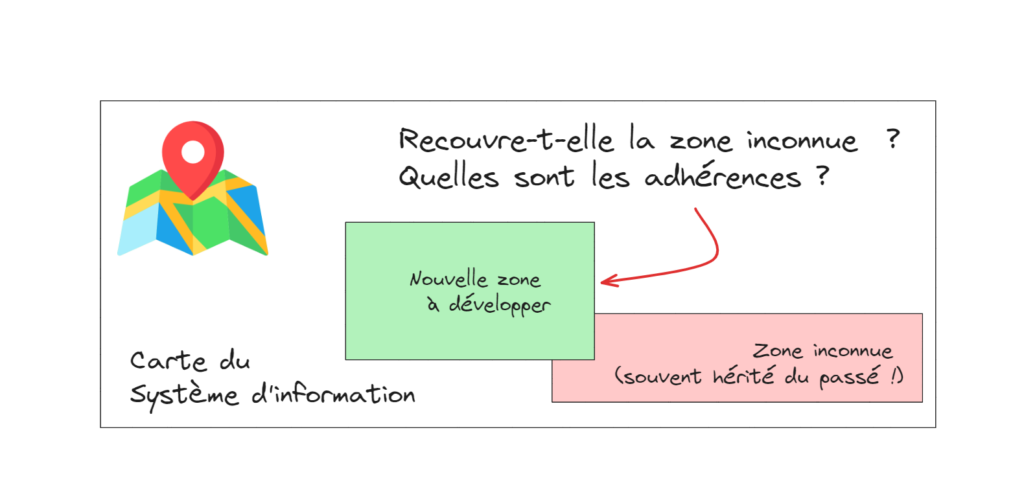
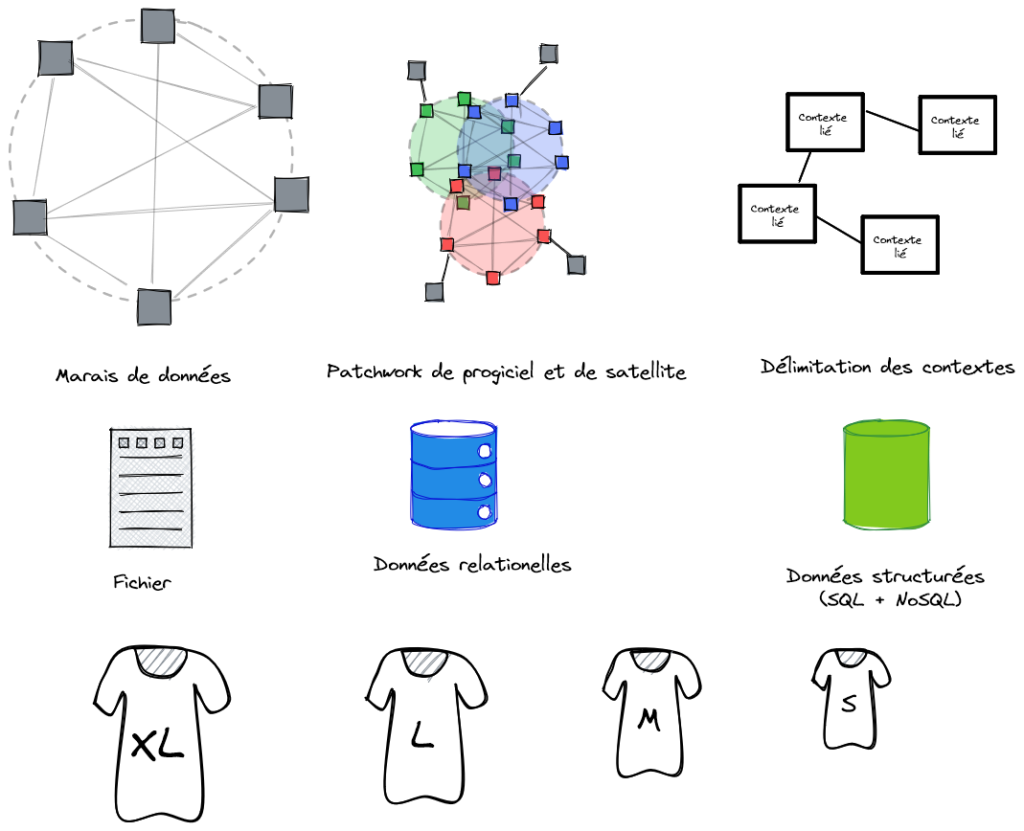
Un système d’information mal cartographié perd sa capacité d’évolution. Mais au moment d’une refonte majeure, la machine s’enraye. On découvre alors que le SI, sans carte ni rangement, ressemble plus à un grenier encombré qu’à un patrimoine maîtrisé ! Comment faire ?
Un système d’information mal cartographié perd sa capacité d’évolution. On empile des briques, on multiplie les adhérences, et tout semble à peu près fonctionner tant qu’on ajoute simplement des fonctionnalités. Mais au moment d’une refonte majeure — migration cloud, rationalisation post-fusion, changement de socle technologique — la machine s’enraye. On découvre alors que le SI, sans carte ni rangement, ressemble plus à un grenier encombré qu’à un patrimoine maîtrisé.
👉 J’ai déjà écrit sur la cartographie du SI et sur les applications. Cet article est le chaînon suivant : comment donner une nomenclature à ce patrimoine.
Inventorier ne suffit pas
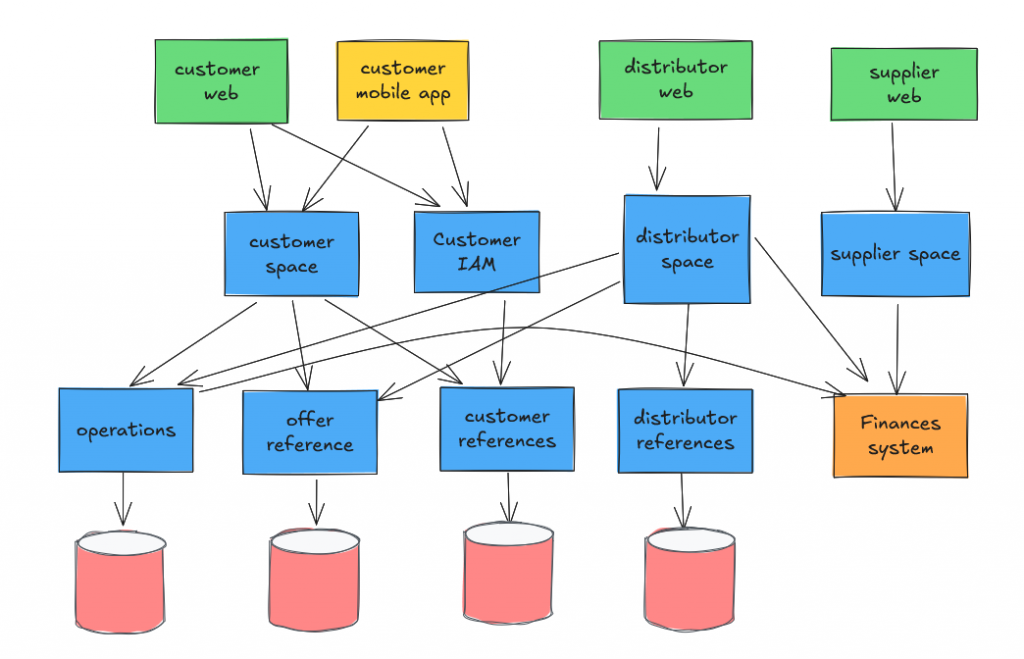
En général, quand je fais la découverte d’un système d’information, cela ressemble souvent au schéma ci-dessous en le multipliant par 10 ou plus. La complexité peut devenir vite redoutable !
La découverte du SI n’est pas forcément immédiate car elle nécessite d’avoir un inventaire applicatif ou de le faire s’il n’existe pas. Parfois, je trouve plusieurs inventaires applicatifs émis par plusieurs sources. Bien sûr, ils ne sont pas cohérents entre eux et la corrélation entre les items demande une certaine dose d’intuition !
Cependant, même si cette étape est nécessaire, elle ne suffit pas pour pouvoir tracer des trajectoires d’évolution du SI. Il faut pouvoir relier le SI à l’organisation afin que l’organisation comprenne comment se mobiliser pour étendre, changer et maintenir le SI. Cela paraît évident … et pourtant ! Il arrive souvent que des parties du SI soient à personne ou à plusieurs. Ces situations créent souvent des frictions.
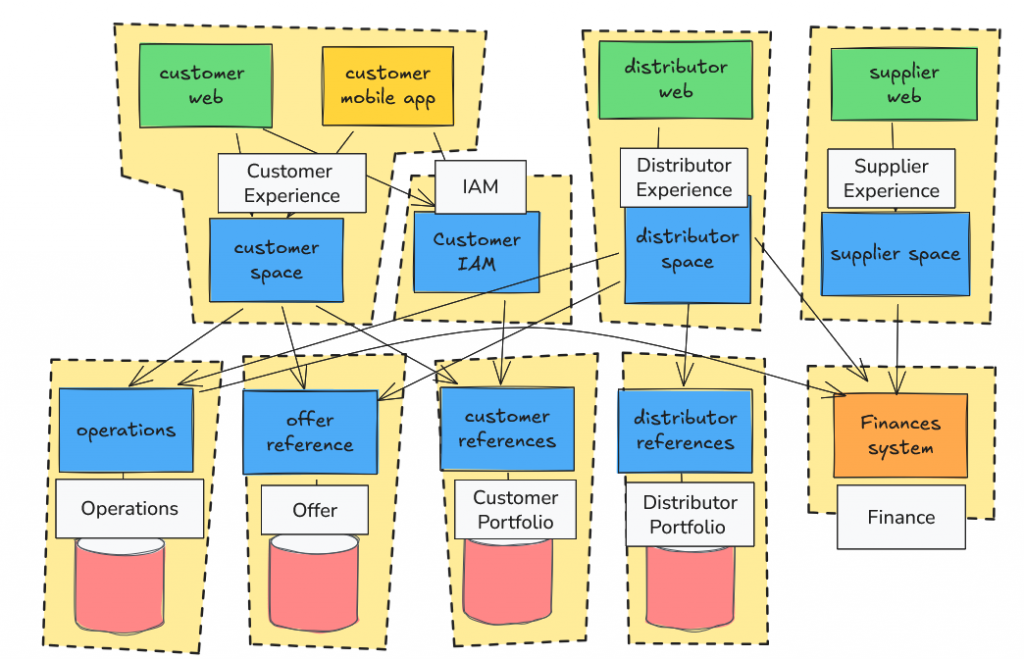
Nous avons besoin de créer un point de vue sur le patrimoine applicatif pour embarquer l’organisation. Afin de simplifier le schéma ci-dessous, nous pouvons regrouper les éléments en agrégat. Idéalement le regroupement a une signification pour le métier (nommé par des termes métier) et pour l’organisation (aligné sur la structure organisationnelle).
La représentation peut ensuite être simplifiée en ne conservant que les agrégats. On peut envisager de les ranger dans une Business Capabilité Map (BCM) ou dans une représentation visuelle type tableau des éléments périodique !
Les applications comme boîtes de rangement
Pour cartographier, il faut doc ranger. Et ce qu’on range dans le SI, ce sont des applications. L’application devient la boîte de référence : elle regroupe des fonctions, des données, des flux, et c’est sur elle que l’on raisonne pour décider si on conserve, remplace, modernise ou externalise.
Pourquoi ne pas utiliser l’unité de déploiement pour clé de rangement ? Avec le temps, l’unité de déploiement est devenue de plus en plus petite. On peut citer les architectures en micro-service ou en micro-frontend. Les SI deviennent ainsi découpés très finement. Il n’est pas rare de trouver plus de 2000 composants pour un SI d’une entreprise moyenne. Il est évident que travailler à cette échelle est très complexe et que l’alternative qui consiste à raisonner plutôt sur une centaine d’application est pragmatique.
Encore faut-il que cette boîte ait une identité stable. Sinon, on se retrouve avec une application qui change de nom selon les projets, qui se fond dans un programme puis ressurgit ailleurs, ou qui prend le nom du progiciel sur lequel elle est bâtie. Bref : impossible de suivre son histoire.
Le code applicatif : une identité stable
La réponse, c’est le code applicatif : une clé unique et durable, qui traverse tout le cycle de vie de l’application.
Le nom peut changer (souvent pour des raisons de communication), le code reste.
C’est ce code qui devient le label fédérateur : on le retrouve dans les workloads, les bases de données, les journaux, les rapports, les sauvegardes, les noms des machines, les flux réseau…
En systématisant la codification des assets de l’IT par rapport au code applicatif, on en tire des bénéfices à long terme :
Le cout de possession des applications se calcule comme la consolidation des couts des assets associés au code applicatif (couts directs) et la réimputation partielle des couts des assets communs (couts indirects).
Les assets orphelins sont un indice de ressources inutilisées ou un signalement d’un défaut organisationnel.
Relier applications et composants
Les développeurs, eux, travaillent sur des composants : des unités déployables. Pour que la nomenclature fonctionne, chaque composant doit porter le code de l’application à laquelle il appartient. C’est ce qui permet de relier la boîte (l’application) à ses briques techniques.
En faisant du composant un élément d’une application, il ne peut appartenir qu’à une seule application. Comme une application appartient à une seule équipe fonctionnelle et est opéré par une seule équipe IT, il n’y a pas d’ambiguïté sur le cadre de responsabilité du composant.
Donner du sens : typer les composants
Tous les composants ne sont pas égaux. Pour les ranger, il faut une typologie.
De mon expérience, trois critères suffisent :
Lieu de déploiement : chez le client, dans le SI interne ou chez un tiers.
État : service applicatif ou base de données (persistant ou non).
Mainteneur : interne ou tiers.
Avec ça, on obtient une règle de nommage simple :
[code applicatif]-[type composant]-[qualificatif]
Un exemple de types de composants courants :
Type de composant
Libellé
Lieu de déploiement
Etat
Mainteneur
app
Application mobile
client
sans
interne
web
Application Web
client
avec
interne
api
Service applicatif
SI
sans
interne
db
Base de données
SI
avec
interne
prg
Progiciel
SI
avec
tiers
saas
SaaS
Tiers
avec
tiers
Encadré pratique : exemple de nomenclature
Code applicatif
Type composant
Qualificatif
Nommage
paie
api
main
paie-api-main
paie
db
main
paie-db-main
paie
web
main
paie-web-main
paie
saas
studio
paie-saas-studio
finance
saas
sap
finance-saas-sap
Cette discipline rejoint les pratiques de l’APM (Application Portfolio Management) décrites par MEGA, LeanIX, Ardoq : avoir une nomenclature standardisée, claire et unique est ce qui permet de comparer les applications, d’identifier les doublons, et surtout de prendre des décisions stratégiques.
APM et Product Management : un rendez-vous manqué ?
L’APM existe depuis plus d’une décennie. Il propose un cadre clair pour inventorier, évaluer et rationaliser le portefeuille applicatif. Sur le papier, l’APM devrait être incontournable — or il reste souvent cantonné aux directions architecture ou urbanisme, perçu comme une démarche “d’ingénieurs de la cartographie”.
Pourquoi ? Parce que, pendant ce temps, l’agilité et le product management ont changé le vocabulaire et les priorités. Là où l’APM range et classifie, le product management valorise, priorise et fait évoluer. On a d’un côté une logique patrimoniale et transverse, de l’autre une logique opérationnelle et orientée produit.
👉 Le paradoxe, c’est qu’il s’agit en réalité de deux faces de la même pièce : le product management gère la valeur courante, l’APM gère la soutenabilité dans le temps.
Deux flux orthogonaux : projets et patrimoine
On peut représenter le SI comme traversé par deux flux :
Les projets : financés, pilotés, visibles. Ils incarnent “l’argent bien dépensé”, car ils créent des nouveautés.
Le patrimoine : maintenance, mises à jour, obsolescence. Il incarne “la dépense forcée”, qu’on subit plus qu’on ne la choisit.
Historiquement, l’organisation a séparé les deux, créant une fracture :
le projet est glorifié,
le patrimoine est toléré.
L’agilité a tenté de dépasser cette contradiction en fusionnant projet et patrimoine dans la même unité : le produit. Le product management va encore plus loin en donnant une équipe, un budget et une feuille de route à chaque produit.
La limite : les programmes transverses
Mais la fusion n’est pas toujours possible. Lorsqu’on conduit un programme transverse (par exemple : rationaliser tout le domaine finance, ou remplacer un progiciel de référence), on sort du périmètre d’un produit. On touche à des morceaux multiples du patrimoine, qui n’ont pas été pensés pour évoluer ensemble.
Et c’est là que l’APM redevient critique :
il donne la vision transverse,
il révèle les doublons et les adhérences,
il permet d’arbitrer rationnellement au-delà du périmètre produit.
En ce sens, l’APM ne s’oppose pas au product management : il l’encadre et le complète.
Conclusion : ranger pour évoluer
Un patrimoine applicatif, c’est comme une bibliothèque. Tant que les livres n’ont pas de code et qu’ils ne sont pas rangés dans des catégories claires, on peut toujours lire, mais on ne retrouve rien et on ne remplace rien sans douleur.
Avec un code applicatif unique et une nomenclature simple, on passe d’un grenier en désordre à une bibliothèque organisée. Et surtout, on redonne au SI ce qui lui manque le plus souvent : sa capacité d’évolution.
Réaliser et opérer une application dans le système d’information implique d’allouer des moyens économiques et des équipes. En revanche, il est plus difficile de comprendre, voire de mesurer la valeur qu’apporte cette application.
Une chose n’a pas une valeur parce qu’elle coûte, comme on le suppose, mais elle coûte parce qu’elle a une valeur.
Daniel Webster, Discours de 1826
Réaliser et opérer une application dans le système d’information implique d’allouer des moyens économiques et des équipes. En revanche, il est plus difficile de comprendre, voire de mesurer la valeur qu’apporte cette application. Et pour répondre à cette problématique, une autre question peut être posée : d’où vient la valeur de l’application ? De là, une approche peut être posée pour soit optimiser l’allocation de moyen pour maximiser la production de valeur (efficience), soit accélérer le flux de valeur à moyen constant (vélocité) (en fonction de la conjoncture !)
Valeur économique
L’application n’a pas de valeur en soi. C’est son intégration dans le système d’information et dans les processus métier qui permet à l’organisation d’opérer efficacement et de réaliser sa mission, qu’elle soit économique ou associative. Comment évaluer sa quote-part dans la « valeur ajoutée » de l’organisation ?
L’application, vue comme un chainon dans la chaine de valeur
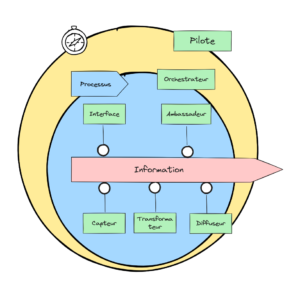
L’application peut contribuer aux processus d’entreprise en réalisant une activité, en renforçant l’intégrité du processus ou en donnant des indications pour améliorer le processus. On peut schématiquement lister ces rôles :
Capteur : Capter une donnée
Transformateur : Transformer une donnée ou la combiner avec une autre donnée
Diffuseur : Exposer une donnée
Interface : Réaliser une interaction avec un acteur humain (client, collaborateur…)
Ambassadeur : Réaliser une interaction avec une autre organisation ou entité, dans l’écosystème de l’organisation.
Orchestrateur : Tenir l’avancement d’un processus et renforcer sa cohérence
Pilote : Consolider des indicateurs dans le passé ou des estimateurs dans le futur pour aider au pilotage du processus et à son amélioration.
Les rôles informationnels de l’application
Le processus a une importance (ou criticité) dans l’organisation qui est évaluable. En revanche, il est plus compliqué de lui donner une valeur économique : les processus opérationnels sont liés à du cashflow tandis que d’autres ne le sont pas directement tout en étant nécessaires au bon fonctionnement (fonction support et pilote). Les démarches visant à faire ruisseler la valeur économique dans les équipes (showback et chargeback) sont méritantes, mais restent complexes et subjectives.
Évaluer la valeur de l’application comme contribution à l’organisation est une approche certes fondée, mais difficile à faire. S’il est possible de rattacher une application à un ou plusieurs processus, comment d’une part définir la quote-part de l’application dans le processus et valoriser le processus lui-même ?
En revanche, il est possible de définir des indicateurs clés de performance (ou Key Performance Indicator, KPI) sur les processus et mettre le coût de possession de l’application (ou Total Cost of Ownership, TCO) au regard des KPI. Le ratio du TCO sur le KPI (ou une somme pondérée de KPI) peut donner une indication de la pertinence économique de l’application. Par exemple :
Une marketplace prend 5% du chiffre d’affaires en commission. Si la marketplace permet d’augmenter suffisamment le chiffre d’affaires pour compenser la perte de marge unitaire, c’est un bon calcul.
Une application de gestion d’offre bancaire supporte à coût constant une augmentation du PNB d’un facteur 5. Cela peut motiver à reverser une partie des gains économiques pour poursuivre l’entretien et la modernisation de cette application.
En considérant l’évolution dans le temps du ratio TCO sur KPI, on peut apprécier les gains d’efficience de l’application ou au contraire sa dégradation. La maintenance d’une application peut dégager une performance si l’application gagne en efficience.
Valeur Métier
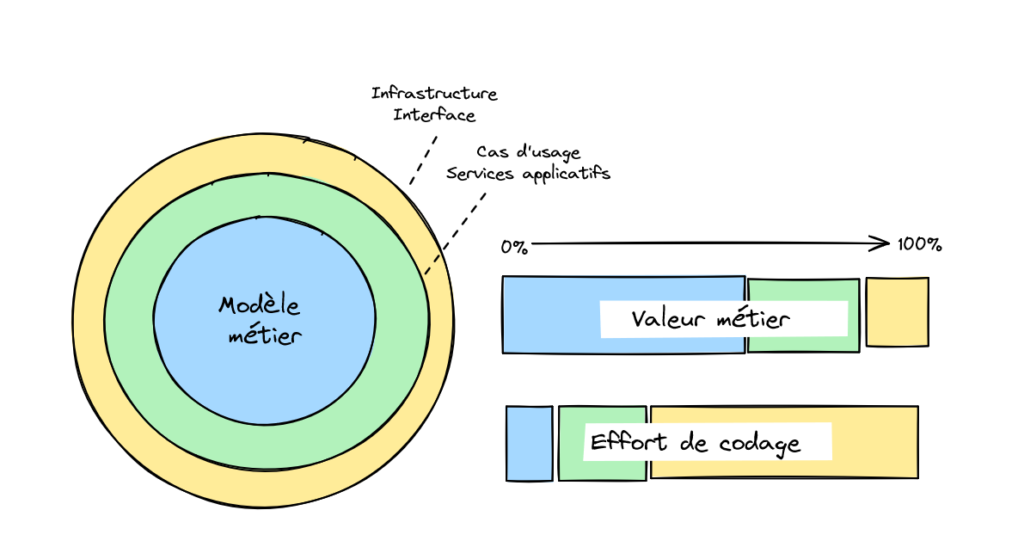
L’application réalise des cas d’usages (comment ?) autour d’un modèle métier (quoi ?) avec un niveau de qualité requis (traduisible par les exigences non fonctionnelles). Sa valeur est donc fonction de la qualité de l’implémentation des cas d’usage et de l’adéquation du modèle métier au contexte.
Quand le cas d’usage est bien implémenté, la cinématique proposée fluidifie le parcours utilisateur, l’exposition à l’utilisateur est intuitive (en écran ou en API) et le comportement du système est prévisible. Quant au modèle métier, on cherche à disposer d’un vocabulaire fonctionnel commun et précis (Ubiquitous Language), d’une organisation de concept permettant de décrire des cas simples, mais aussi des cas avancés de façon élégante et d’une capacité à gérer l’écart avec la réalité.
L’application évolue naturellement avec le mode opératoire de l’organisation. Les cas d’usage sont donc susceptibles de changer plus vite que le modèle métier. Aussi, la valeur issue des cas d’usage demande un investissement régulier pour se maintenir. A contrario, l’effort sur le modèle métier produit une valeur plus durable.
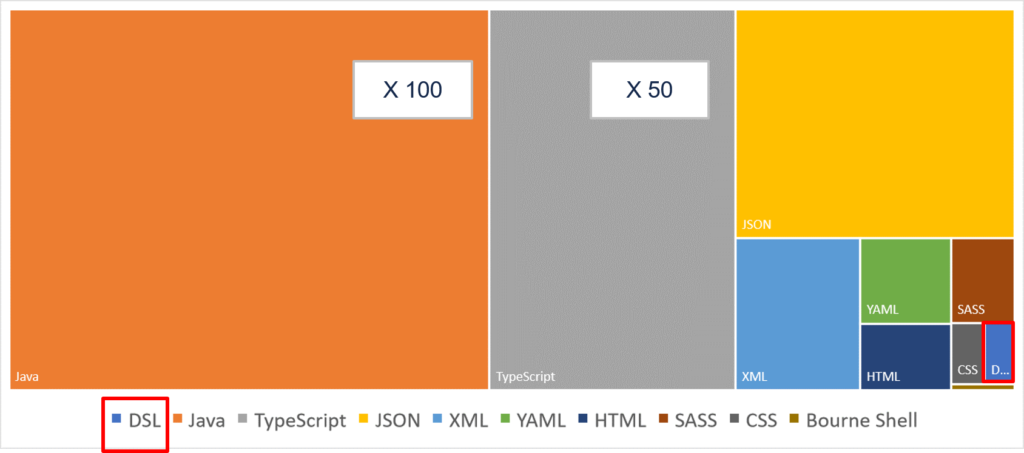
Le code lié à la définition et à la manipulation du modèle métier représente une part mineure du code.
Pour illustrer ce point, considérons un composant applicatif qui expose une entité par une API REST. En utilisant JHipster, il est possible de le générer à partir d’un DSL décrivant le modèle métier. Cette génération produit une implémentation tout à fait honorable : cache de persistance, internationalisation, contrôle d’accès, tests, interface d’administration… Le DSL représente seulement 1% de la totalité du code généré.
Cette génération automatique démontre que la valeur de ce composant dépend entièrement de ce 1% de code. On pourrait objecter que ce cas est limite. Pourtant, il est observé régulièrement, bien qu’il puisse poser un certain nombre de problèmes, à commencer par l’observation de l’anti-pattern, le domaine anémique.
Plan de masse du code d’un composant d’exposition API REST
Dans la production de la valeur métier, on dépasse la loi de Pareto qui pourrait s’exprimer comme « 20% du code est responsable de 80% de la valeur ». Le ratio est encore plus prononcé : quelques pourcents sont à l’origine de quasiment toute la valeur ! On pourrait appuyer ce propos en considérant que la plupart des fonctionnalités ne sont pas utilisées (voir le rapport Chaos à ce sujet, même si c’est une source un peu ancienne.).
La loi de Pareto appliquée à la valeur métier du code.
Aussi, la conception est une étape clé dans la production de la valeur métier. La construction du modèle métier doit être pensée soigneusement afin de donner à l’application une fondation solide. C’est néanmoins une étape négligée pour « gagner du temps » dans le but de tenir les premiers jalons. Y compris dans une approche agile, la dette sur le modèle métier est difficile à rattraper.
Valeur technique
The trouble with quick and dirty is that dirty remains long after quick has been forgotten.
La qualité de l’application se constate par l’atteinte d’exigences techniques (disponibilité, intégrité, sécurité, performance…). Plus le niveau d’exigence est élevée, plus l’application se doit d’être de qualité. Le propos semble évident. Et pourtant ! Combien de fois attend-on d’une réalisation en quick and dirty une qualité dans l’exécution du service ?
La capacité d’une application à répondre à des exigences élevées (haute disponibilité, haute performance, haute sécurité…) est en soi une force. Une conception avancée et un soin particulier dans l’implémentation sont alors requis. Des démarches de qualité logicielle comme le Software Craftsmanship fournissent souvent le substrat culturel de telles organisations.
La valeur de l’application peut résider essentiellement dans la qualité. Par exemple, des applications peuvent adresser un modèle métier concis et des cas d’usage simple et supporter des charges de travail importantes avec une grande efficience. Elles permettent à leur organisation de baisser les coûts unitaires des services d’une organisation et prendre des parts de marché.
La qualité de l’application peut être mesurée par un indicateur calculé automatiquement comme la Fitness Function.
Pour que la qualité compte, il est nécessaire de s’assurer de son adéquation au besoin et donc de qualifier les exigences techniques. Également, il convient de mesurer l’atteinte des exigences de façon factuelle pendant l’exécution du service de façon à rendre cette qualité tangible. Sans ces deux conditions, la qualité n’est ni reliée au besoin, ni rendue crédible auprès des stakeholders et donc finit par sortir du contexte de travail.
Conclusion
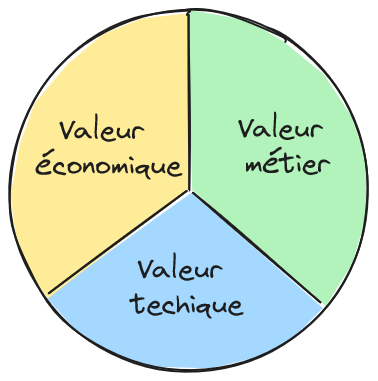
La valeur de l’application peut être considérée au travers de 3 axes complémentaires :
La valeur économique, définie comme la contribution de l’application à la performance des processus par la mesure du ratio KPI/TCO ;
La valeur métier s’exprimant comme la concision du modèle métier à décrire le contexte métier et à évoluer avec et aussi l’efficacité des cas d’usage ;
La valeur technique décrite comme la capacité à respecter des exigences techniques.
Pour que les applications délivrent la valeur attendue, une démarche active est nécessaire afin d’orienter les feuilles de route pour aller chercher plus de valeur et motiver les efforts pour protéger la valeur existante de l’entropie et de l’obsolescence. À l’inverse, quand la valeur de l’application n’est pas considérée, les efforts peuvent être dispersés dans la multiplication de quick wins qui finissent par atteindre la disposition de l’application à continuer de produire de la valeur et donc sa pérennité.
La plupart des SI ne disposent pas de cartographie réellement opérationnelle, Comment alors mettre en place une cartographie pour redécouvrir le territoire ?
Pour tout randonneur, une carte est bien utile pour savoir où on est et quel chemin prendre pour aller là où on veut. De même, pour un système d’information, une équipe informatique a besoin de s’appuyer sur une cartographie pour adapter le SI aux enjeux du métier, sans parler de l’optimiser ou simplement de le maintenir en état de fonctionnement. Pourtant, la plupart des SI ne disposent pas de cartographie réellement opérationnelle, à la fois utile, utilisable et utilisée. Alors, comment mettre en place des cartographies qui repoussent l’inconnu, le Here be dragons des cartes anciennes ?
Après une période de développement des SI, beaucoup d’entreprise doivent aujourd’hui revoir leur cœur de SI – qui est obsolète, ou non adapté à la nouvelle configuration du marché -, ou optimiser leur portefeuille d’application pour réduire les coûts de possession en impactant le moins possible le service rendu au métier. Sans la carte du territoire, ces chantiers d’adaptation ou de transformations sont risqués et compliqués, et finissent être en retard et coûteux (s’ils finissent !). On construit rarement sur du green field : le brown field est quand même la situation la plus rencontrée.
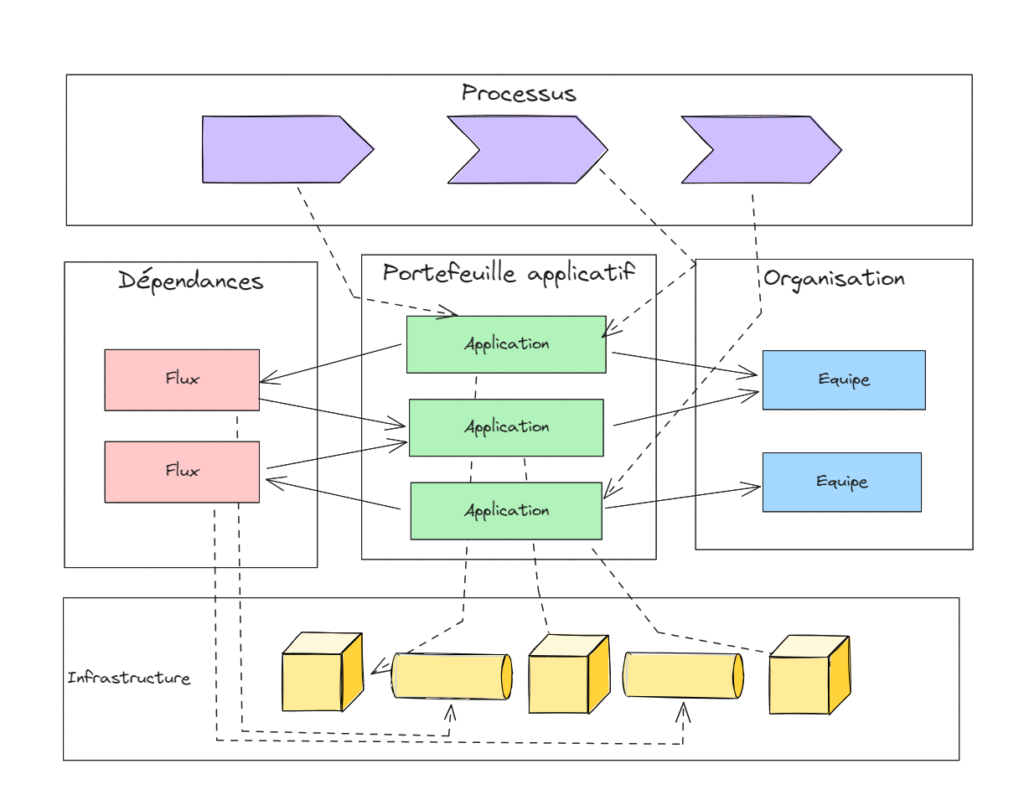
Que trouve-t-on dans une cartographie de SI ?
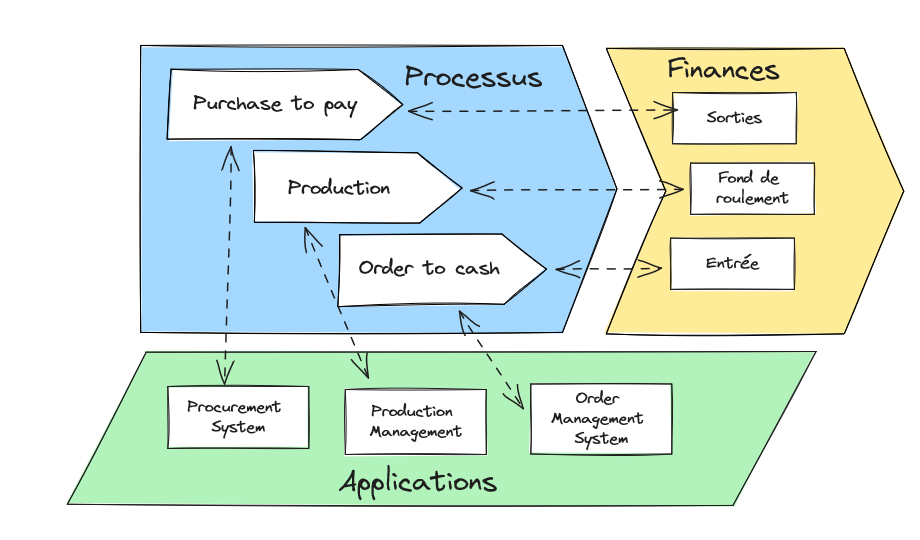
Que contient une cartographie de SI ? A minima, elle contient le portefeuille applicatif, sa projection dans l’organisation, les dépendances entre ces éléments. Le portefeuille applicatif est l’inventaire de l’ensemble des applications et de leurs constituants. La projection dans l’organisation est le découpage des périmètres de responsabilité (et de financement) de ce même portefeuille. Enfin, les dépendances peuvent se comprendre comme des flux de données, définissant des relations producteur-consommateur entre applications. Ces éléments sont nécessaires pour appréhender le SI comme un système socio-technique : la combinaison d’éléments informatiques et de savoir-faire humains produit (ou devrait produire) une valeur supérieure à la somme des valeurs unitaires.
Ce noyau de cartographie est souvent complété par une projection du SI sur l’infrastructure, c’est-à-dire le déploiement des éléments applicatifs sur les ressources techniques. Cette information est généralement conservée et exploitée dans une CMDB (qui peut avoir les mêmes problèmes de fraîcheur et d’exhaustivité !). Elle sert à exploiter le parc technique pour atteindre les engagements de niveau de service, et potentiellement à l’optimiser sur un plan économique, dans une approche de FinOps.
Pour les cartographies les plus avancées, nous avons aussi une mise en correspondance entre le SI et les processus Métier, qui établit le lien entre les activités de processus et les éléments applicatifs. Cette relation fournit les dépendances entre le modèle opérationnel de l’organisation et le parc applicatif et d’identifier les « applications critiques », celles qui supportent les processus Métier les plus importants. Cette compréhension est utile pour orienter les efforts sur les enjeux métier. L’allocation des efforts n’est pas si évidente que l’on pourrait le penser, car elle doit tenir compte des dépendances entre applications. En effet, pour qu’un service métier soit rendu, toute la chaîne applicative qui le sous-tend doit fonctionner de bout en bout. . Par exemple, un bus de service qui n’a pas de valeur métier en soi, hérite souvent de la criticité des applications métier qu’il supporte. On peut aller encore plus loin en s’appuyant sur ce lien entre SI et processus pour rechercher l’efficience du SI en fonction de la valeur métier induite. Cette approche offre une alternative mieux-disante à la recherche de la réduction du coût absolu du SI (voir cet autre article du blog, Pour un nouveau contrat entre le métier et l’IT).
Structure de la cartographie du SI
La difficulté à disposer d’une bonne cartographie
Pour qu’une cartographie puisse apporter de la valeur, elle doit être suffisamment à jour, suffisamment complète, suffisamment manipulable et intelligible par la plupart des acteurs et suffisamment employée dans la planification et la mise en œuvre des changements du SI. En matière de cartographie, la perfection n’est pas nécessaire. De toute façon, la carte n’est pas le territoire1 ! L’approximation est acceptable si les erreurs potentielles sont facilement détectables et réparables par les acteurs, que ce soit par des procédures ou des contrôles automatiques. Dans ces conditions, les acteurs ont une confiance fondée à s’appuyer sur la cartographie pour analyser le SI et prendre des décisions pertinentes sur les trajectoires des projets.
Une carte n’est pas le territoire qu’elle représente, mais, si elle est juste, possède une structure similaire à ce territoire, ce qui justifie son utilité
A Non-Aristotelian System and its Necessity for Rigour in Mathematics and Physics, Alfred Korzybski, 1931
Malheureusement, beaucoup de cartographies sont trop approximatives. Les acteurs doivent alors aller à la pêche aux informations et vérifier systématiquement toutes les informations présentées. Le bénéfice de la cartographie s’évapore complètement. Cette situation s’explique par la tragédie des communs2 : tout le monde bénéficierait d’une cartographie opérationnelle, mais personne n’a le temps/l’envie/la compétence (rayez la mention inutile) pour la mettre à jour. Ce conflit entre intérêt collectif et intérêt individuel peut être résolu par la gouvernance du système d’information, qui promeut les comportements de bons citoyens et instruit les écarts par rapport à cette norme. Les acteurs ont donc des incitations pour mieux coopérer entre eux. Ne haïssez pas les joueurs, mais le jeu3 !
Approche classique de mise en place de la cartographie
Dans une approche classique, les équipes produisent les dossiers d’architecture des applications, en responsabilité, et reversent les éléments d’information dans une base de connaissance commune, ladite cartographie. Le dossier d’architecture spécifie notamment l’implantation de l’application dans le SI : comment l’application interagit avec le reste du SI ? comment est-elle déployée au travers de l’ensemble de ses environnements ? comment cette implantation va se réaliser dans le temps ? La cartographie du SI est à la fois l’unification de ces « cartes locales » mais aussi la piste chronologie de la carte globale. Elle décrit à la fois l’état présent du SI, mais aussi l’état projeté au travers de plusieurs trajectoires (l’état passé peut aussi être intéressant dans le cas de rétrospective). En s’appuyant sur la cartographie, les acteurs construisent une compréhension commune de la situation, mais aussi s’entendent sur la cohérence de leurs plans d’action.
Assemblage de la cartographie globale du SI
La cartographie du SI est parfois assimilé comme le dossier d'architecture du SI. Cela me semble être une erreur 🫣.
Le dossier d'architecture ne se résume pas à des schémas d'implémentation ! Il contient tout un raisonnement qui conduit des enjeux métier aux exigences non fonctionnelles, puis aux choix d'implémentation et à la spécification des environnements. Ce raisonnement permet de comprendre l'existant et peut être remis en cause de façon consciente pour s'adapter à de nouvelles circonstances.
De l'autre côté, la cartographie doit rester à un niveau de simplification suffisant pour rester exploitable. Bien sûr, quand on arrive sur une application dans la carte, il est intéressant de joindre le dossier d'architecture de celle-ci pour "creuser".
Si on fait une analogie dans le monde du bâtiment, le plan cadastral nous donne l'organisation des parcelles tandis que le plan technique du bâtiment implanté sur la parcelle décrit sa structure. Le plan cadastral serait sûrement lourd à consulter s'il contenait la description détaillée des bâtiments.
Comment faire une cartographie en rétrospective ?
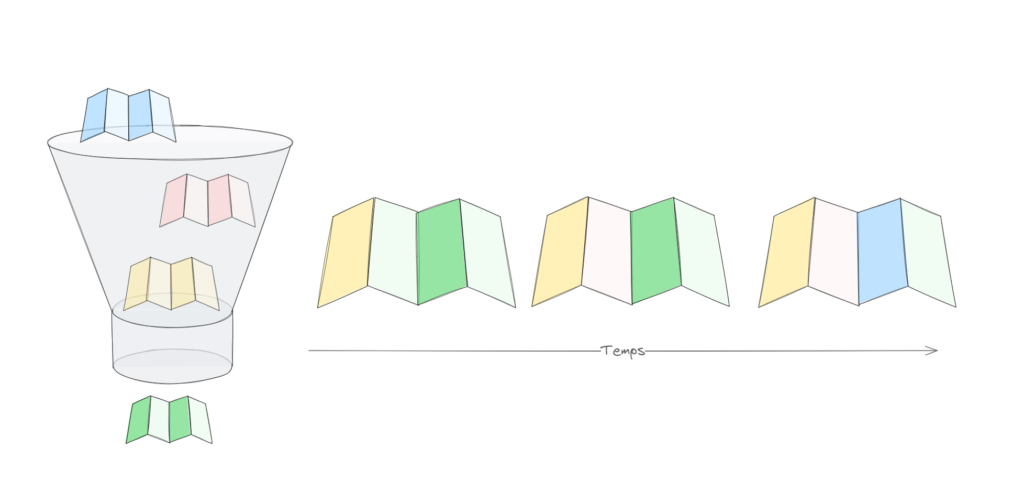
Et comment faire une cartographie si on n’a pas suivi cette approche classique ? Dans cette situation, on constate souvent une documentation écrite incomplète, non actualisée, voire absente ! La connaissance est dans la tête des acteurs (enfin, c’est ce qu’ils imaginent !) et ces derniers n’ont pas l’idée de renseigner une cartographie spontanément (vous vous rappelez la tragédie des communs ?). Les produits du marché visent la population des architectes, qui ne représentent qu’une toute petite fraction de la DSI et sont parfois jugés comme trop complexes pour les autres acteurs de la DSI. Dans ces conditions, les architectes collectent les informations et sont les seuls à renseigner le référentiel. Certes, nous avons une cartographie utile et utilisable, mais pas utilisée par le plus grand nombre 😞. Et cela dépend d’un effort important concentré sur un petit nombre d’acteurs, un effort qui se démultiplie quand il s’agit de reprendre l’existant (le fameux Here be dragons). Un autre frein dans cette démarche est le processus d’achat du produit. Il est compliqué de faire entendre le ROI d’une cartographie pour motiver cet achat. La perte de temps de la pêche aux informations ou les opérations « coup de poing » d’inventaire d’existant sont difficiles à valoriser pour alimenter le business case de l’achat du produit de cartographie.
Et si on doit démarrer léger ?
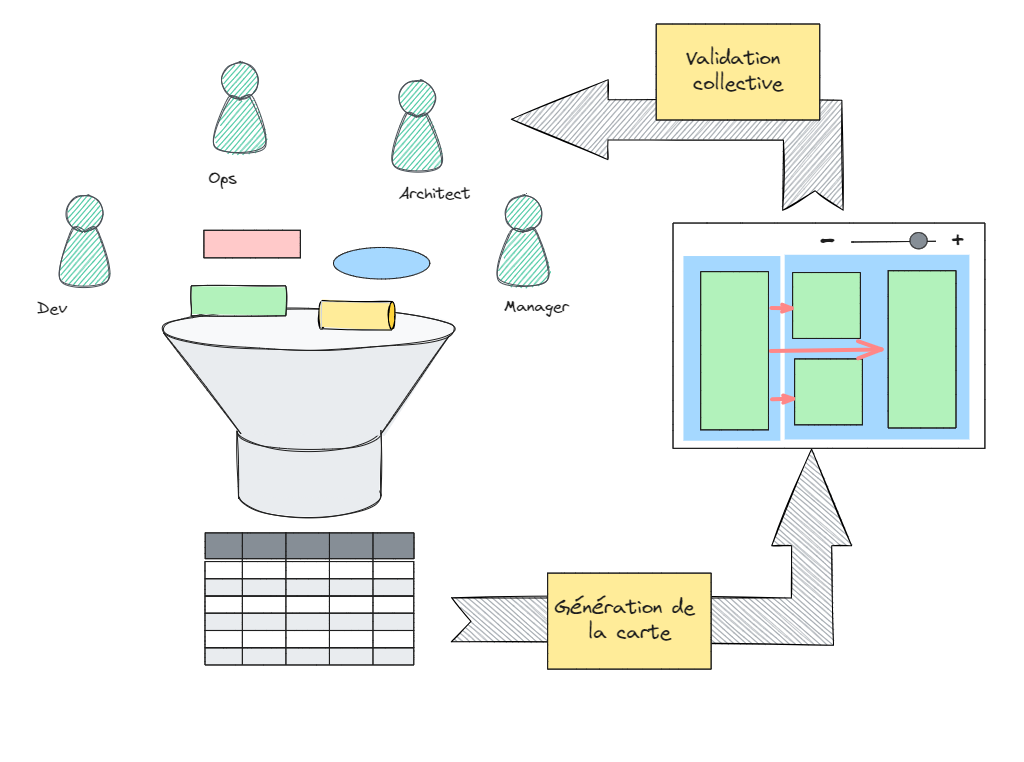
L’année dernière, j’ai eu l’opportunité de construire une alternative plus légère pour initier une cartographie sur tout ou partie du SI et commencer à explorer le Here be dragons. Elle se déroule en deux temps : une phase de collecte dans des feuilles de calcul, suivie d’une phase de contrôle basée sur une représentation graphique dynamique, affichable avec cet excellent outil qu’est Ilograph. L’affichage permet de valider en séance les renseignements collectés avec l’ensemble des acteurs. Cette approche permet de rassembler et de croiser le savoir des acteurs, qu’ils soient managers, développeurs ou opérateurs.
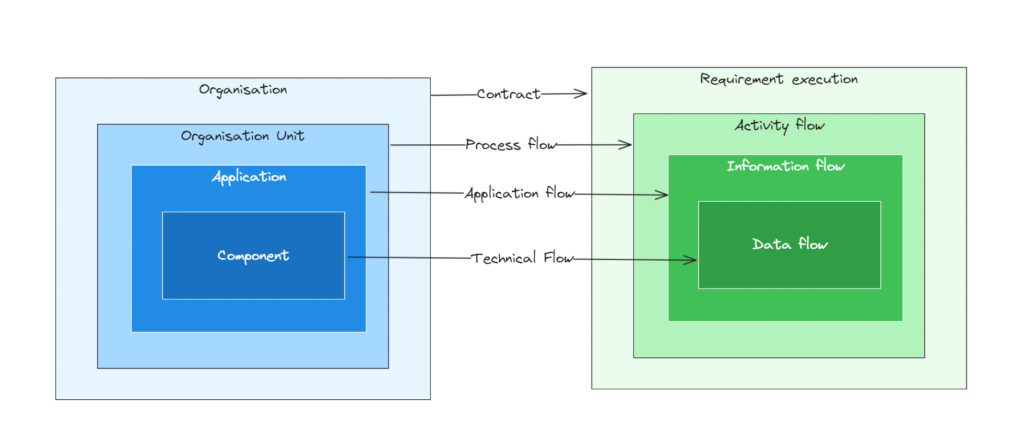
La modélisation du SI est volontairement simple. Le portefeuille applicatif est un ensemble de ressources organisé en une série de poupées gigognes : les organisations sont divisées en unités organisationnelles ; les unités organisationnelles sont en charges d’applications et ces applications sont implémentées par des composants. Le concept d’application est ici central, positionné entre l’organisation humaine et les composants déployés (voir Et pour vous, qu’est-ce qu’une application ?). Un point important dans cet exercice est d’identifier tous les éléments (et donc de fournir un identifiant à chacun). Curieusement, il n’y a pas toujours d’identifiant fixe et universel de disponible (par exemple, un code applicatif pour désigner une application). Dans ce cas, il faudra produire de façon arbitraire un identifiant pour poursuivre la démarche. Le tout premier bénéfice de la cartographie est de pouvoir nommer sans ambiguïté les constituants du SI 🙂 !
Proessus de rétrocartographie
Ensuite, on formalise les flux d’informations entre les applications, les flux applicatifs. Les flux sont des abstractions au-dessus des flux techniques qui correspondent à des ouvertures de réseau. Pour reconstituer les flux applicatifs, on recherche leurs points de passage avec l’aide des opérateurs. Un point de passage peut être un job dans un ordonnanceur, un label d’un transfert de fichier, une souscription sur une API… Un flux applicatif est fréquemment composé de plusieurs flux techniques. De même, que pour les ressources, les flux sont identifiés.
Méta-modèle de cartographie
La feuille de calcul est un bon support pour ce cas d’usage. Les acteurs sont habitués à ce format documentaire. Ce format est flexible : on peut ajouter des champs supplémentaires qui apportent une information pertinente dans le contexte.
L’export des données de la feuille de calcul vers un diagramme Ilograph est réalisé par un script Python, développé pour l’occasion. Ce script peut être adapté pour prendre en compte des particularités.
Le diagramme Ilograph fournit une représentation graphique bien adapté à des sessions de travail en groupe. On peut modifier à la volée l’affichage, en choisissant un niveau dans l’organisation des ressources (d’où l’intérêt des poupées gigognes plus haut) ou sélectionnant l’élément central à représenter. Il est possible d’adapter l’affichage en fonction du point abordé. Un autre intérêt par rapport à d’autres solutions de diagramming est la meilleure tolérance pour afficher des systèmes avec beaucoup de flux. Comme les systèmes d’information sont de plus en plus distribués, on a besoin de solutions qui nous permettent d’afficher ces graphes sans qu’ils ressemblent à une toile d’araignée (c’est joli, mais pas très utile ! ).
Il est aussi possible de compléter le modèle pour inclure les trajectoires de transformation de SI. C’est un point que je suis en train d’expérimenter (et ce sera sans doute l’objet d’un prochain article 😉).
TL;DR
Cartographier le SI est donc une activité essentielle de la DSI, dans le contexte actuel. Cette activité peut être découpée en deux volets : la cartographie des nouveaux pans du SI et celle de l’existant.
La cartographie des nouveaux pans implique de remettre de l’architecture intentionnelle dans la démarche des projets ou des itérations : instruire les dossiers d’architecture peut être une pratique à démarrer ou restaurer. Certes, il ne s’agit plus maintenant de produire des corpus documentaires volumineux comme avant, mais de réaliser une documentation efficace s’appuyant sur des pratiques modernes comme les ADR pour instruire les choix ou les DSL pour produire les schémas d’architecture.
La cartographie de l’existant implique de pouvoir récupérer la connaissance sur le SI qu’elle soit sur des supports écrits ou dans la tête des sachants et de la mettre en qualité.
Prioriser la remise en état de la connaissance du SI reste une tâche difficile. Aussi, une approche légère et itérative, comme décrite précédemment, peut amorcer un cercle vertueux qui démontre les bénéfices de disposer d’une cartographie du SI avec un investissement minimal. Ensuite, le passage vers une approche plus industrielle peut se produire pour fournir une cartographie à l’échelle de l’organisation et pour supporter l’ensemble des trajectoires dans le SI.
« A map is not the territory it represents, but, if correct, it has a similar structure to the territory, which accounts for its usefulness » (A Non-Aristotelian System and its Necessity for Rigour in Mathematics and Physics, Alfred )Korzybski, 1931) ↩︎
Pour éviter le quick & dirty systématique, la définition et la mise en oeuvre des exigences techniques peuvent aider.
La définition des exigences techniques et leur mise en œuvre effective font partie des pratiques les plus difficiles sur les projets informatiques, toutefois nécessaires. Que se passe-t-il quand elles ne sont pas réalisées ? Face à un métier pressé, la solution rapide, dite quick and dirty1, est une option attrayante. Et quand elle est déployée, il est difficile d’avoir l’accord du métier pour la refaire en plus solide. Après tout, le métier a eu ce qu’il veut et ne voit pas, de prime abord, le bénéfice à ce refactoring. La maintenance du code est le problème des informaticiens ! Face à cet aléa moral2, la pratique des exigences techniques peut apporter une réponse.
Les exigences techniques ne sont pas les exigences de l’IT
Les exigences techniques (ou exigences non-fonctionnelles) sont aussi nécessaires que les exigences fonctionnelles pour permettre à l’application (ou au produit) de répondre aux attentes. Une application, qui n’adresserait que des exigences fonctionnelles, serait certes utile, mais pas utilisable et donc pas utilisée (d’où quelques frustrations !). Par exemple, un utilisateur face à une interface lente (problème de performance) ou confronté à des informations peu fiables (manque d’intégrité) ou encore échangeant avec un système non sécurisé (divulgation d’information) finira par trouver d’autres possibilités plus acceptables avec son mode opératoire. À la différence des exigences fonctionnelles, elles ont une portée globale et leur validation passe par d’autres mécanismes que la recette fonctionnelle (tests de performance, tests de sécurité, tests de robustesse, qualimétrie, …).
Les exigences techniques sont désignées de la sorte, car leur validation passe par des moyens techniques et non parce qu’elles sont à l’origine des acteurs IT !
Ce malentendu, probablement dû à un nommage malheureux, peut faire croire aux acteurs Métier qu’ils ne sont pas concernés (ou qu’ils peuvent se sentir légitimes à ne pas les prendre en considération !).
L’acronyme FURPS+ permet de se rappeler une classification des exigences dans leur ensemble. Dans cette méthodologie, le point de départ est un ensemble de questions qui s’adressent au métier pour l’aider à qualifier les exigences. Toutes ces questions sont intéressantes pour le métier.
Fonctionnalité : Que veut-faire le métier ? Les besoins liés à la sécurité sont aussi inclus sous ce terme.
Facilité d’Utilisation : Dans quelle mesure le produit est-il efficace du point de vue de la personne qui s’en sert ?
Résilience : Quel est le temps d’arrêt maximal acceptable pour le système ? Comment redémarrer le service ?
Performance : Quelle doit être la rapidité du système ? Quel est le temps de réponse maximal ? Quel est le débit ?
Supportabilité : Est-il testable, extensible, réparable, installable et configurable ? Peut-il être supervisé ?
Le ‘+’ final désigne des considérations IT qui peuvent ne pas intéresser directement le métier telles les contraintes de conception, d’implémentation ou encore de déploiement. Toutefois, leur mise en œuvre affecte la qualité du produit et concerne in fine le métier.
Piloter la complexité du SI
Les architectes sont garants de la bonne santé du système d’information, mais aussi de la proportionnalité des moyens alloués par rapport aux objectifs attendus. Cela se traduit par la maitrise de la complexité du SI dans un cadre spatio-temporel.
Sur un plan spatial, la complexité devrait être concentrée dans les zones du SI où elle apporte de la valeur. La complexité n’est jamais gratuite ! Le framework Cynefin est une bonne méthode tactique pour adapter la réponse au problème. Pour les situations simples, des solutions simples… et pour des situations complexes, des approches émergentes ! Ce principe semble marquer au coin du bon sens. Pourtant, la tentation des solutions « Et ce serait cool si … » est très forte pour des technophiles et autres adorateurs de la nouveauté. Malheureusement, quand l’effet « cool » s’essouffle, la maintenance devient un problème épineux et les adorateurs de la première heure peuvent être déjà partis… À un niveau plus stratégique, on peut s’appuyer sur le Core Domain Chart est pour prioriser les domaines où insérer de la complexité peut être payant, par exemple pour se différencier (en bien !).
Abordons maintenant la dimension temporelle. La complexité a la fâcheuse propriété à augmenter dans le temps. Cela peut se faire de façon passive avec le phénomène d’entropie, obtenu par un cumul de changements dans le code, dégradant la conception du système, mais aussi de façon active quand l’application répond à de sollicitations de plus en plus grandes. Paradoxalement, une application qui connait une réussite dans son usage peut se voir injecter une dose de complexité qui pourra finir par la tuer, victime de son succès en quelque sorte !
Quand la complexité devient trop importante, l’application n’est plus maintenable et évolutive, ce qui implique sa fin de vie à plus ou moins brève échéance. Les projets en Quick and Dirty 3 arrivent plus vite que les autres à ce stade fatidique.
L’idéal est de réaliser, maintenir et opérer des applications qui atteignent les exigences tout en minimisant la complexité le plus bas possible.
Si les exigences ne sont pas posées, alors la complexité peut ne pas être adaptée au besoin (et c’est souvent le cas, en pratique) que ce soit par insuffisance (une solution simpliste qui ne répond pas au besoin) ou par excès (un « marteau pour écraser une mouche », aussi connu comme l’anti-pattern Marteau doré)
Base du contrat de confiance entre métier et SI
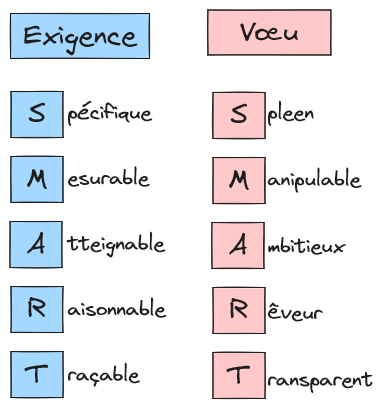
L’exigence peut servir à écrire des articles dans le contrat de confiance entre métier et IT, à condition d’être SMART.
Pour se rappeler ces bonnes caractéristiques, l’acronyme SMART est un bon moyen mnémotechnique.
L’exigence est Spécifique pour ne pas être qu’un souhait.
L’exigence est Mesurable pour ne pas être qu’une promesse en l’air.
L’exigence est Atteignable pour être un engagement sincère.
L’exigence est Raisonnable pour avoir du sens.
L’exigence est Traçable pour être une propriété effective de l’application.
« Faire ce qu’on fit et faire ce qu’on dit » est généralement une bonne pratique pour instaurer une bonne relation de confiance ! L’exigence permet de poser et partager un attendu et de se donner les moyens de l’atteindre effectivement.
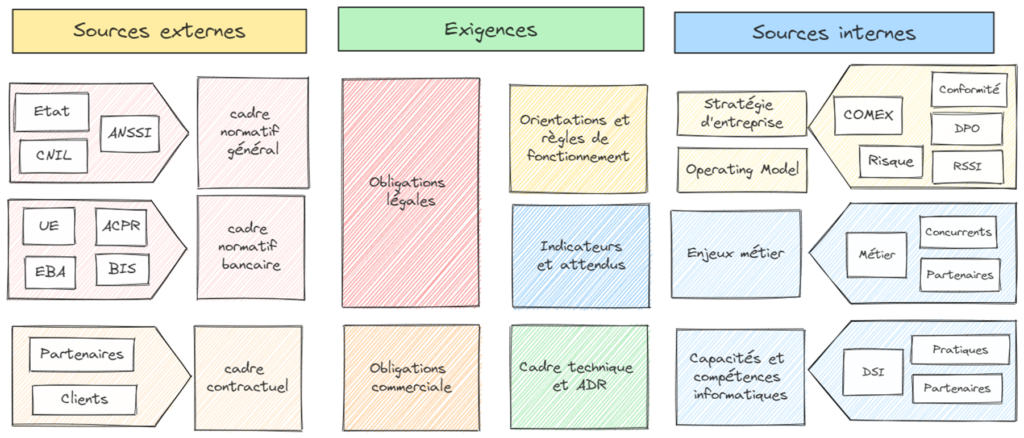
Tout le monde a des attentes !
Toutes les parties prenantes ont des attentes par rapport au SI. Elles peuvent être en dehors du cadre de l’organisation (administrations, partenaires, clients) ou à l’intérieur (direction générale, contrôle interne, direction métier, direction informatique, etc).
Les contributeurs des exigences
Ces attentes peuvent être déclinées en exigences. Entre l’attente et l’exigence, l’écart sera plus ou moins important en fonction du caractère contraignant de l’attente (par exemple, une disposition règlementaire) et de la marge d’interprétation. L’écart pourra être ajusté suite à une négociation.
Il est recommandé de collecter ces attentes le plus tôt possible et non de les découvrir à la fin de l’itération. Une attente pourra être suffisamment contraignante pour remettre en cause une partie de l’implémentation et sans doute le calendrier !
À l’inverse, il ne faut pas être plus royaliste que le roi. Pour les premières itérations, des exigences faibles pourront être acceptables, sachant que les exigences seront redéfinies pour les itérations finales dans des formes plus élevées. C’est un des principes dela Continuous Architecture et de l’ Architecture Runaway.
Comment calibrer les exigences ?
Si l’objet des exigences techniques est bien connue (FURPS+, cela vous parle ? 😉), en revanche le calibrage est plus difficile.
Prenons une exigence portant sur la vitesse d’affichage d’un écran. Comment définir la valeur à atteindre en cible ? Il faut à la fois tenir compte du fonctionnement de l’attention humaine (moins d’une seconde pour garder la fluidité dans l’interaction), des attendus des utilisateurs au travers de leur expérience digitale, que ce soit dans un cadre professionnel ou personnel (les services des GAFAM sont rapides !), et des moyens techniques communément atteignables par une organisation classiques. Une façon d’apporter une réponse est de se comparer au marché. Voulons-nous que l’application se situe dans le 1% des meilleurs, le premier décile, la première moitié ou peu importe ? C’est l’idée des Core Web Vitals, prendre en compte les statistiques de HTTP Archive et construire des cibles par rapport à ce que l’on fait. Une exigence construite sur ce principe a la particularité de varier dans le temps, car chaque année, le niveau peut monter (et même baisser, c’est possible).
Pour d’autres exigences plus normatives comme la sécurité ou l’accessibilité, il existe des normes avec des niveaux de conformité plus ou moins élevées à aller chercher (RGAA pour l’accessibilité, OWASP pour la sécurité, par exemple).
Le compétiteur ou la référence du marché peut aussi donner des idées. La concurrence a du bon ! C’est souvent un bon argument pour ajuster l’exigence à un niveau à la fois performant et raisonnable.
Et si malgré tout, on ne trouve pas toujours pas d’inspiration, on pourra se référer sur les référentiels d’exigences classiques comme DICT. Si les niveaux élevés de DICT sont atteignables par les moyens techniques mis à dispositions par les hyperscalers, les limites posées par la capacité financière et par l’organisation de l’exploitation restent toujours à adresser.
Passer du besoin à l’exigence
Les attentes peuvent être, au départ, implicites ou alors abstraites. Cela peut conduire à plusieurs écueils :
Le demandeur formule une exigence absolue (par exemple, une demande d’une disponibilité à 100%). La motivation peut être une aversion au risque (et un transfert de responsabilité à l’IT). Le demandeur peut aussi ne pas comprendre en quoi cette question le concerne alors que la qualité du résultat dépend du niveau d’exigence.
Le demandeur renvoie la question à l’IT en demandant ce qu’elle peut fournir au mieux.
Le demandeur n’a qu’une seule exigence, qu’il n’y a pas de problème ! 😒
Fournir un catalogue de niveau de service sur lequel l’IT peut s’engager est une bonne base de discussion. Ce catalogue consiste en une liste d’exigences SMART organisées par niveau de service.
Cela permet de ne pas partir d’une feuille blanche et de disposer d’un format synthétique pour faciliter les échanges. De plus, plus que 90% des applications rentrent certainement dans des niveaux standards. On a donc un gain de temps significatif dans la qualification des exigences. Cela permet de se concentrer sur les quelques applications critiques qui vont nécessiter des moyens particuliers pour atteindre des niveaux de service très élevés.
Disposer d’un niveau de service minimal permet de définir dans tous les cas un engagement explicite, y compris unilatéralement. Et si ce niveau ne correspond aux attentes effectives lors d’incident, alors il est toujours possible de requalifier le niveau de service et de lancer un chantier de remédiation.
Passer de l’exigence au business case
À ce stade, nous disposons d’exigences SMART. Elles sont suffisamment claires pour pouvoir évaluer les conséquences concrètes sur la construction et l’exploitation des applications. Nous disposons de bases pour estimer l’effort de fabrication, mais aussi le cout de fonctionnement.
Les exigences peuvent s’avérer trop onéreuses au regard de la valeur attendue ou alors trop complexes à mener au vu des ressources de l’organisation. À ce moment, le demandeur peut revoir le besoin afin d’améliorer le business case de la solution ou sécuriser sa mise en œuvre.
L’ajustement des exigences pour adapter l’effort à la valeur attendue permet de mettre le projet sur des bases équilibrées : le bon niveau d’effort pour le bon résultat attendu. Quand le métier et l’IT sortent tous les deux gagnants dans la réalisation du business case et dans la mise en place du produit, c’est une situation plutôt satisfaisante ! Pour cela, même si les exigences demandent de prendre un chemin parfois difficile, la récompense à l’arrivée en vaut la peine !
Le cache de donnée, bien que performant et répandu, a mauvaise presse. Même si l’invalidation de cache reste un sujet complexe, le jeu en vaut la chandelle !
Le cache, mal aimé et pourtant indispensable
La réputation du cache de données dans le monde de l’informatique est bien curieuse. Son usage est largement répandu. Pour autant, le cache apparaît comme une complication ou même un risque avec la corruption de cache. Comme toute technique puissante, elle peut avoir des conséquences désastreuses par un mauvais emploi. Il est temps de faire le plaidoyer du cache et lui redonner sa place légitime !
La sortie rapide de la salle d’attente
Le cache est employé à différente échelle dans les systèmes informatiques, du microprocesseur jusqu’au réseau Internet. Le cache est un levier de performance très puissant, en substituant une opération lente par un accès rapide en mémoire. Les applications passent l’essentiel de leur temps dans une sorte de salle d’attente. Le cache est, en quelque sorte, une sortie rapide dans cette salle d’attente ! Réduire le temps de présence des applications dans la salle d’attente est un moyen particulièrement efficace pour accélérer leur fonctionnement, juste après celui de la mise à disposition de ressources suffisantes aux applications (traitement, mémoire, réseau, stockage).
Piste rapide ou lente ? Cache ou pas cache ?
La déraisonnable efficacité du cache
Pour que le cache soit effectif, il faut non seulement qu’il dispose d’une alternative rapide aux opérations réelles, mais aussi qu’il puisse effectuer cette substitution dans un « bon nombre » de cas. La fréquence de substitution applicable s’appelle le cache hit rate. Il n’y a rien d’évident à ce que le taux de hit soit élevé, de l’ordre de 80%, et indépendant de la taille relative du cache par rapport au volume des données opérationnelles. Le cache s’appuie sur une heuristique qui se vérifie dans les cas courants : la localité temporelle et spatiale. Généralement, un utilisateur travaille sur une zone locale de l’espace des données (un agrégat fonctionnel, par exemple) dans un intervalle de temps délimité. Ce mode opératoire conduit naturellement le cache à avoir un taux de hit élevé, même sans préchauffage de cache.
Heuristique du cache
À la rescousse de l’expérience utilisateur
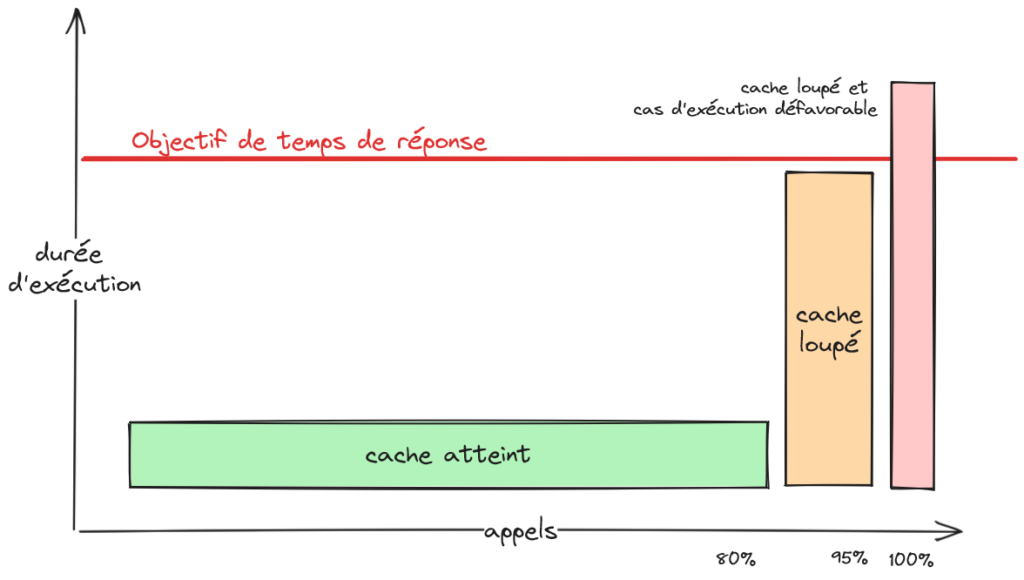
Le cache améliore le ressenti utilisateur même s’il ne suffit pas à lui seul à atteindre l’objectif de temps de réponse. Par exemple, le taux de hit peut atteindre 80% quand on vise dans 95% des cas à rester sous la barre des 3 secondes de temps de réponse. Pour autant, le ressenti utilisateur sera meilleur avec une réponse rapide dans 80% des cas. C’est sur ce principe qu’est calculé l’indice Apdex qui évalue le ressenti des clients finaux quant à la performance.
Cache et performance
À l’inverse, une application trop lente devient inutilisable et les utilisateurs finaux expriment alors leur rejet. Cette lenteur est souvent causée par des opérations d’entrée-sortie (I/O) trop nombreuses ou trop lentes (voire les deux !). Le cache est particulièrement efficace dans ce genre de situation, en remplaçant ces opérations lentes par des équivalents nettement plus rapides. La mise en place et la configuration de cache ont aussi le bon gout de ne pas trop altérer le code et de réduire les risques de régression. C’est donc une méthode efficace et rapide de résolution de problème de performance, quand elle est applicable (ce qui n’est malheureusement pas toujours le cas 🙁 ). Elle m’a permis de redresser des projets, à plusieurs reprises dans ma carrière. Au passage, la performance apparaît comme une des rares caractéristiques d’architecture qui soit perceptible dans l’expérience des utilisateurs finaux ! C’est un élément tangible de ce que peut apporter la pratique d’architecture aux projets d’informatique.
Protection contre la charge
Le cache est aussi un réducteur de la consommation des ressources. Il évite de réaliser sans cesse des opérations qui produisent le même résultat. Outre le gain d’efficience évident, le cache évite la saturation des ressources qui va provoquer une dérive du système. Le cache peut ainsi être vu comme une mesure de protection contre un nombre de sollicitations trop important, qu’il soit intentionnel (par exemple, une attaque DDoS) ou non. J’avais eu le cas d’un site Internet saturé à cause du traitement des sollicitations des agrégateurs RSS qui prenaient plus de 90% de la capacité de traitement. La mise en cache des flux RSS a résolu la situation. Dans cette veine, on peut citer la conception Jamstack qui permet de remplacer un site Web dynamique par un site statique facile à mettre en cache et aussi à distribuer, autour du monde.
Le cache peut aussi nous faire faire des économies. La mémoire coute moins cher que le CPU. Il vaut donc mieux mettre un résultat stable en mémoire que le recalculer. Avec une allocation de 4 Go par CPU sur les gabarits habituels de machine, la mémoire est de facto très abondante.
Le problème de l’invalidation du cache
There are only two hard things in Computer Science: cache invalidation and naming things.
Phil Karlton
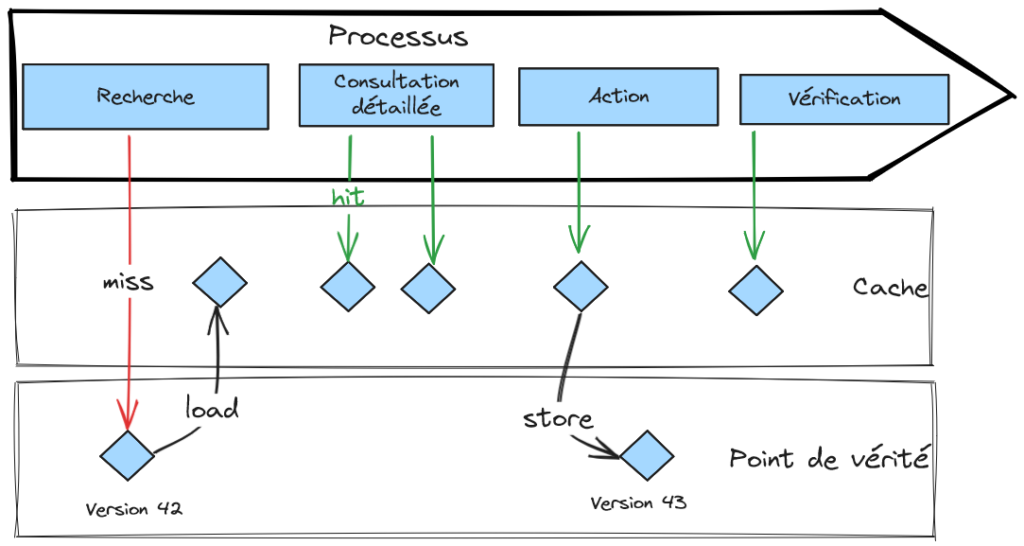
Mais, alors, pourquoi avec toutes ces qualités, le cache n’a-t-il pas bonne presse ? Le problème est que le cache peut être corrompu, c’est-à-dire contenir des données qui ne sont plus à jour, donc fausses. Les utilisateurs peuvent alors être induits en erreur et prendre de mauvaises décisions. Enlever les données dépassées du cache (ou les remplacer par des données fraiches), c’est ce que l’on appelle invalider le cache. Il n’existe pas, dans le cas général, de méthode efficace, correcte et performante pour invalider le cache, une méthode qui à la fois donne un taux de hit du cache élevé (efficace), évite l’utilisation des données dépassées (correcte) et n’introduit pas de blocage (performante). La raison profonde est qu’il est difficile d’établir un consensus entre la source de vérité et le cache, sans qu’à un moment, il n’y ait une suspension pour la synchronisation. On peut faire une analogie avec le problème des généraux byzantins, que l’on rencontre dans le monde des blockchains.
La résolution de l’invalidation par la maitrise du point de vérité
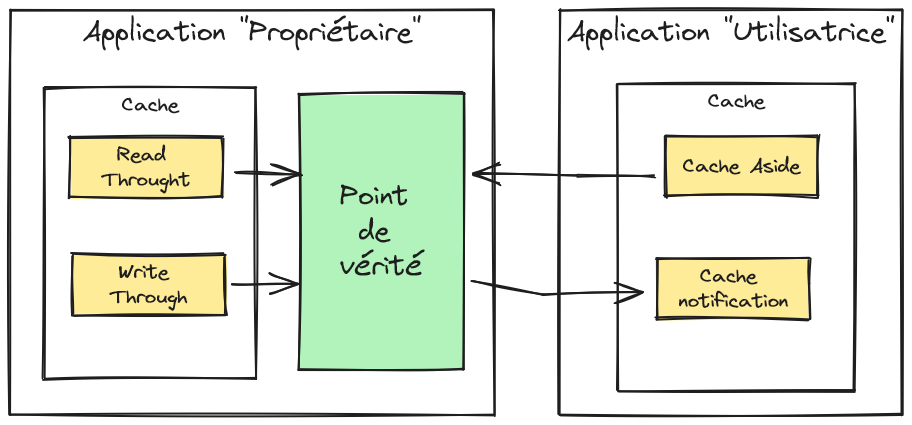
Le cache peut être réputé non corrompu dans plusieurs cas particuliers, en établissant une acceptation de la fraîcheur du cache sous un ensemble de condition. Le cas le plus favorable est quand l’application qui porte le cache dispose aussi du point de vérité de façon unique. Elle peut alors garantir que le cache est mis à jour « en même temps » que le point de vérité. Cela correspond aux stratégies de cache, Read Through et Write Through. Quand l’application est déployée en plusieurs instances (ce qui est maintenant la norme), ce cas demeure applicable si l’implémentation du cache supporte la distribution et fournit une sémantique garantissant l’atomicité des opérations sur le cache. Le deuxième cas, un peu moins favorable, est quand l’application qui a le cache reçoit des notifications de la source de vérité. L’application peut considérer le cache comme à jour au délai près de la notification. Évidemment, le délai de notification n’est pas borné et peut dériver en cas de forte charge. Il faudra prendre en considération cette situation dégradée. Enfin, l’application peut accepter d’utiliser des données dépassées pour les opérations en lecture, mais toujours justes lors des opérations d’écriture (on vérifie alors que le cache est bien en accord avec la source de vérité, il s’agit de méthode de verrou optimiste).
Cache, propriétaire et utilisateur
La résolution de l’invalidation par le cycle de vie de la donnée
Il existe une façon plus puissante d’avoir un cache à jour qui dépend du cycle de vie de la donnée. La donnée immuable est la donnée idéale pour un cache ! Malheureusement, rien n’est vraiment immuable dans notre monde. Le changement est la seule constante dans la vie ! En revanche, on trouve facilement des données stables, des données dont l’état change dans une échelle de temps sensiblement plus grande que la durée des processus fonctionnels. Par exemple, nous avons un produit en vente. Son prix est révisé tous les mois et la durée du tunnel de vente est rapide, moins d’une heure. Dans ce contexte, le prix du produit est une donnée stable. On peut gérer les données stables avec la notion de durée de vie (Time To Live) qui permet de faire une invalidation dans un mode distribué. Si une donnée est versionnable, c’est-à-dire que la version permet de fixer son état de la donnée, alors les versions de la donnée peuvent être mises en cache sans risque de corruption. Enfin, il y a un cas réellement antagoniste à la mise en cache : ce sont les séries chronologiques et les flux de données (data stream).
Cache By Design
Et, si le cache était prévu dès la conception ? On pourrait alors espérer concilier les avantages décrits précédemment tout en mitigeant le risque de données dépassées (Stale data). Il s’agit donc essentiellement de privilégier la manipulation de données immuables.
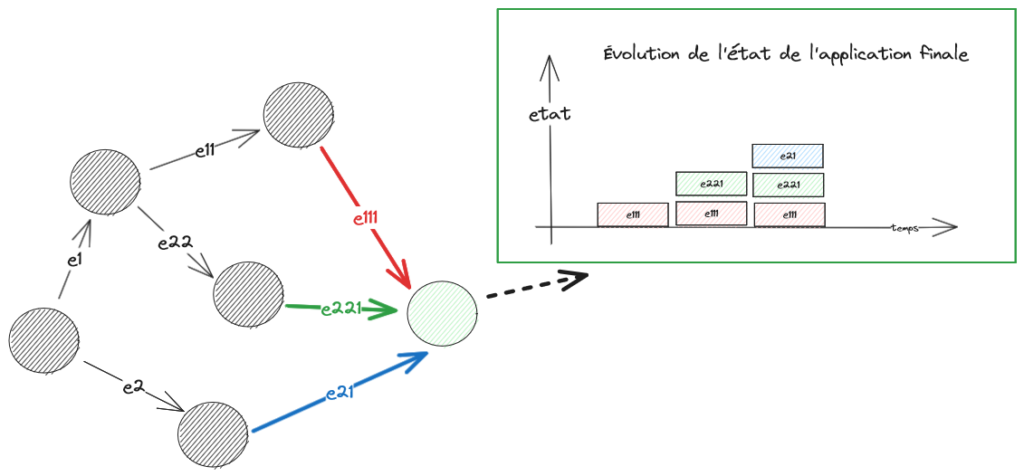
La première approche qui vient en tête est l’Event Sourcing : le changement d’état est défini des événements et l’état est la résultante de la série des événements. Les événements sont des données stables, faciles à propager et à copier. L’état est éventuellement consistant. La cohérence de l’information est assurée à un écart correspondant au délai de propagation global et au taux de perte de transmission des messages. L’état d’une application dépend de la somme des événements reçus et sera altéré par des événements perdus ou arrivés trop tard. Dit comme cela, le degré de confiance dans l’exactitude de l’état peut être faible. Pour autant, l’application est capable de produire un état dans des conditions dégradées dans cette configuration alors qu’elle ne le pourrait pas dans une conception strictement synchrone. Pour revenir à notre sujet, les événements sont de bons candidats à mettre en cache et le calcul de l’état peut se faire en mémoire.
Event sourcing
Sur le schéma ci-dessus, le graphe de propagation des événements a la qualité d’être acyclique, ce qui permet de garantir la stabilité de l’état à terme. En présence de cycle, la définition de l’état stable pour l’ensemble du système est plus problématique.
Une autre approche, moins classique, consiste à tracer les versions des objets et aussi les versions des objets antécédents, un peu à la façon d’une Horloge de Lamport. Les versions des objets sont mises en cache comme elles sont immuables. Il est également possible de détecter quand nous manipulons une version d’objet alors qu’une plus récente est disponible et de pouvoir traiter ces cas de corruption de cache. Comment ? L’Horloge de Lamport va nous aider.
Prenons le cas ci-dessous. Nous avons des émetteurs de versions d’objets. À chaque émission, la version est incrémentée. Également, dans les transmissions, nous communiquons la version de l’objet, mais aussi celle de ses antécédents. Par exemple, B émet un message vers C indiquant qu’il envoie la version 2 de B, construite avec la version 1 de A. Si le message de E arrive avant C ou D, un risque de corruption se présente, car la version 2 de A va être ingérée avant la version 1. On peut le voir autrement, F va récupérer des versions de C et D en retard avec la version de A qu’il a reçu. De façon générale, on a un risque d’incohérence globale. Le cas idéal est quand les versions des objets à chaque point du système ne font que croitre (ce sont des fonctions monotoniques).
La détection pourrait être réalisée à chaud, avec un différé correspondant au délai de propagation des messages estimé, comme dans le cas de l’Event Sourcing. Mais, on peut aussi opter pour une approche à froid : la détection est alors plus efficiente et a un degré de confiance plus élevée. L’approche à froid est séduisante, car on peut s’appuyer sur cette heuristique : la plupart des corruptions de cache n’ont pas de conséquence. En effet, la donnée peut être mise à jour un plus tard et une réparation se fait souvent lors de cette mise à jour. Ou encore la donnée est conservée à titre de mémoire et n’est pas ensuite exploitée. Rares sont les cas où une mauvaise décision est prise alors que la donnée n’est pas à jour et ne peut être compensée. Un corollaire à cette heuristique est la mauvaise qualité des données dans le système d’information qui malgré tout fonctionne.
Effectivement, les approches de Cache By Design sont plus avancées que celles rencontrées habituellement. Pour autant, elles peuvent aller chercher la performance supplémentaire requis pour certains besoins. En architecture, la réponse est souvent : « ça dépend … » 🙂
En ces temps incertains, la vitesse d’adaptation au contexte est une capacité utile à la survie des organisations. Les doutes peuvent survenir et abimer la relation de partenariat entre métier et IT. Si l’IT n’a pas toujours tenu ses promesses en délai et en qualité ou si l’IT demande trop de ressources au regard de la valeur produite, le métier peut se demander si l’IT sera à la hauteur pour délivrer sa stratégie digitale. Si le métier n’affiche pas sa vision et ne partage pas ses objectifs, l’IT peut se voir être mis « à la mine ». La confiance prend du temps à se construire et la méfiance en met moins !
La fourniture de solutions opérées par des tiers, en mode SaaS ou de solutions éditables par des Citizen Developers donne au métier un sentiment de libération en cassant le monopôle de la production et du développement de l’IT. Et si le métier faisait de l’informatique sans l’IT, pour voir ce que cela donne ? Le métier peut économiser du budget en faisant du DIY, lancer plus facilement des expérimentations et mobiliser moins de ressources dans les processus de projet informatique. Si cela peut libérer les énergies, on peut s’interroger sur les effets à long terme (et même à moyen terme) sur le Système d’Information : complexité, hétérogénéité, « raccords humains » entre les briques du SI, etc.
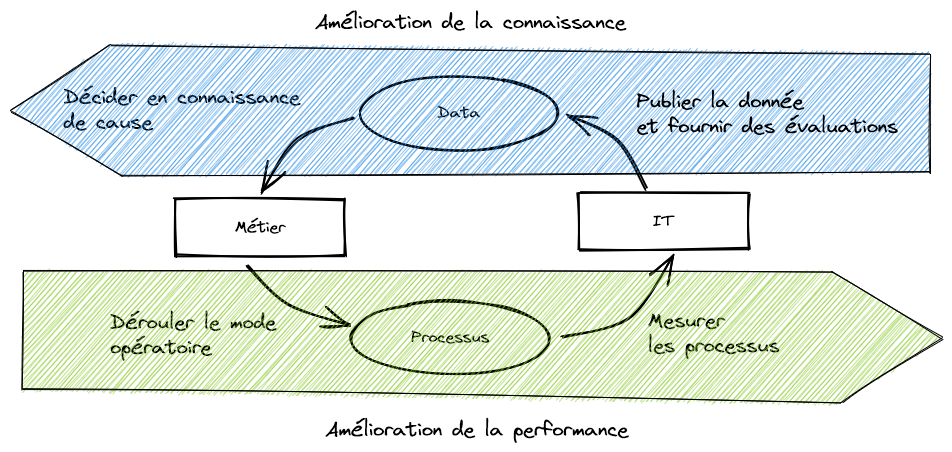
Comment poser un contrat gagnant-gagnant entre le métier et l’IT ? Le métier a besoin de dérouler son mode opératoire d’une façon de plus en plus efficace. L’IT peut lui donner les moyens de mesurer l’enchainement de ces processus et identifier les axes d’amélioration. En connaissant les processus, l’IT comprend mieux le fonctionnement du métier, développe son empathie fonctionnelle et améliore sa force de proposition. Le métier a besoin des données du SI pour comprendre le contexte et prendre les bonnes décisions. L’IT peut lui donner leur état, mais aussi la construction qui a conduit à ses états. Ainsi, le métier peut remonter aux phénomènes générateurs des données. Le Système d’Information devient le bien commun entre le métier et l’IT.
Le cycle vertueux qui lie le métier et l’IT
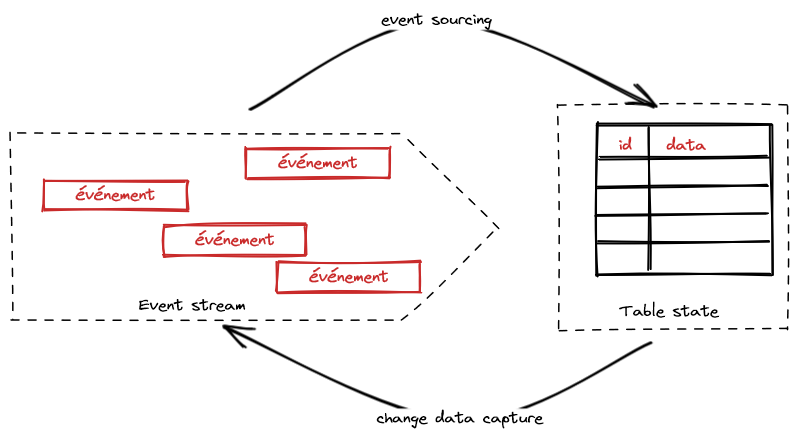
Le Système d’Information devrait appréhender de manière équitable les processus et les données. Si le Système d’Information n’adresse que les processus, il peut se réduire à un System of Engagement incomplet, à côté de processus entièrement manuels. Si le Système d’Information n’adresse que les données, il peut se limiter à être un Système of Record partiel, posé à côté d’autres silos de donnée. La combinaison des processus et de la donnée donne une incitation à la complétude du système d’information. Par ailleurs, la qualité de la donnée résulte de la bonne exécution du processus et la preuve du bon déroulement du processus vient de la véracité de la donnée.
La relation entre processus et donnée est une conséquence de la dualité entre événements et états. L’idée est développée dans la conception de Kafka Streams. Le flux d’événements (stream) remplit une table d’état et les changements de la table d’état sont en soi des événements. La construction de l’état à partir d’événement est désigné par Event Sourcing et l’extraction d’événements à partir de changement d’état est la technique de Change Data Capture (CDC).
Dualité Événement/État
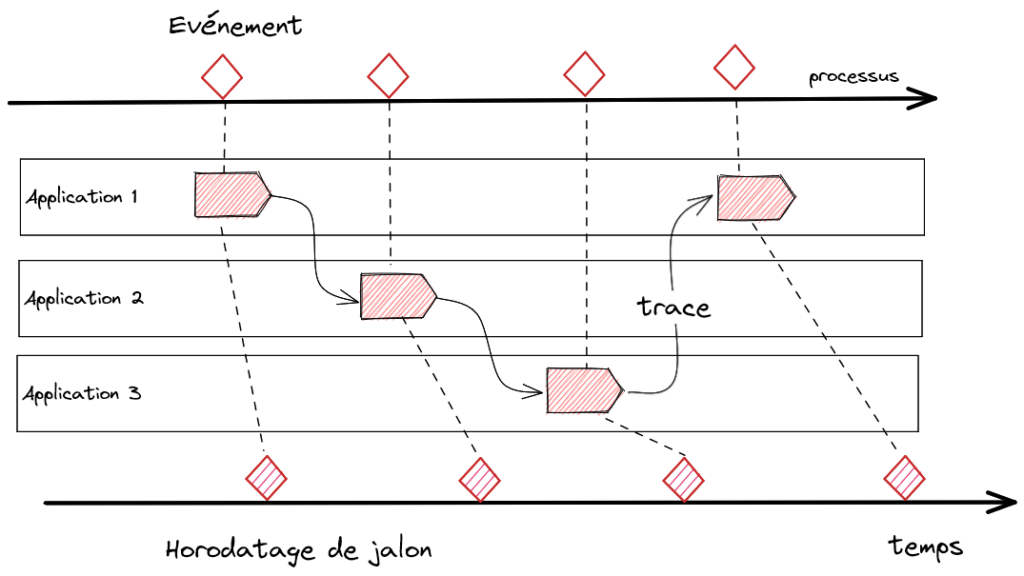
Si l’IT est parfois démuni pour identifier des cas d’usage sur la donnée, l’IT dispose en revanche de moyens modernes et efficaces pour instrumenter les processus. Les processus sont balisés par une chronologie d’événements, séquentielle ou non. Les événements peuvent maintenant être des citoyens de premier ordre dans le SI avec les ateliers d’Event Storming, la conception par Domain Driven Design, l’implémentation d’Event Sourcing. La propagation des événements dans le SI peut se faire efficacement en utilisant l’instrumentation de l’Application Performance Management (APM). La consolidation de ces informations d’exécution, Processus – Événement – Trace, permet de juger du succès et de la vélocité des processus. Ces informations sont utiles au métier qui peut identifier des améliorations dans les procédures fonctionnelles et au métier qui peut proposer des améliorations tactiques (RPA, optimisation de performance) ou plus radicales (refonte de composants).
Processus, événements et traces
Le métier et l’IT devrait plus s’inspirer mutuellement. Quand le métier valorise la donnée, l’IT ne se sert pas suffisamment de la donnée pour améliorer son fonctionnement. L’IT peut très bien déployer un SI data-centric sans être data-centric. Quand l’IT promeut la qualité par les processus (gestion de projet, ITIL, …), le métier déroule des procédures sans conscientiser les processus. Le métier peut très bien pousser une approche processus-centric sans être processus-centric. Ce paradoxe étonnant peut être résolu par une relation de collaboration sincère et profonde entre métier et IT.
En mettant en œuvre un SI exploitant la synergie entre processus et donnée, l’IT et le métier peuvent trouver un terrain favorable à une collaboration fructueuse dans une logique gagnant-gagnant.
Petit conte sur la modernisation du SI, au travers de l’univers du Petit Prince.
J'ai écrit ce petit conte philosophique sur la modernisation du SI, inspiré très librement du Petit Prince d'Antoine de Saint-Exupéry. C'est une œuvre profonde avec plusieurs niveaux de compréhension. On pourra trouver des clés d'interprétation sur ce site et aussi celui-ci pour une approche plus initiatique. En écrivant ce texte, j'ai pensé chaleureusement à d'anciens collègues qui m'ont fait un cadeau bien à propos avec cet article. Ils se reconnaitront :-)
Bonne lecture !
Crédits pour les images : Succession Saint Exupéry-d’Agay
Le SI vieillit. Le coût du changement devient prohibitif et l’inertie empêche de suivre les tendances du marché. Les volcans ne sont plus ramonés. Les baobabs ont envahi le paysage applicatif. Le métier exprime des insatisfactions et des inquiétudes vis-à-vis de l’IT.
Le Petit Prince du SI va chercher de l’aide et s’envole avec les oiseaux. Dans son périple, il rencontre plusieurs personnages.
Le Roi lui dit « Modernise-le SI, je te l’ordonne ». Il sait donner des ordres raisonnables, car il espère être obéi. Pour autant, cela n’indique comment s’y prendre. Le Petit Prince lui demande de l’enjoindre de partir au coucher du soleil. Ainsi, le Petit Prince prend congé du Roi.
Le Vaniteux lui dit « Moderniser des SI. Oui, je fais cela du matin au soir ! ». Si la reconnaissance des personnes est importante, elle ne suffit pas être le moteur de la modernisation du SI. Certains font des plans magnifiques et partent discrètement quand les difficultés concrètes se manifestent…
Le Buveur se lamente de son sort au milieu du SI qui part en délabrement. Il subit l’état du SI et inconsciemment, contribue à sa dégradation. Il aime les problèmes dont il se plaint !
Le Business Man lui dit « Quel est le ROI de la modernisation ? ». Après tout, cela coute cher d’arracher des Baobabs ! Il est difficile de quantifier le cout du délai à ne pas faire. Une chose est sûre : ne pas changer le SI peut être mortel à la fin pour l’organisation.
L’Allumeur de Réverbère essaye de faire fonctionner jour après jour le SI, en compensant par des gestes réguliers les dysfonctionnements. Grâce à ses efforts consciencieux, le SI continue à fonctionner. Mais jusqu’à quand cela va-t-il tenir ?
Le Géographe connait les théories sur la modernisation du SI, mais n’a pas le temps pour voir sur le terrain ce qu’il se passe. En théorie, il n’y a pas de différence entre la théorie et la pratique. Mais en pratique, il y en a une. (Yogi Berra)
Enfin le Petit Prince arrive sur Terre. Il rencontre l’Aviateur. « S’il te plait, dessine-moi un SI ». Mais pour l’Aviateur, ce n’est pas facile. Il met alors le SI dans une boite pour que le Petit Prince puisse le ramener chez lui.
Le Petit Prince croise le Marchand de Pilule qui vend le remède pour réparer le SI immédiatement. Pourtant, quand on a soif, le mieux est encore d’étancher sa soif. Les Marchands de Pilule ne sont jamais loin des programmes de modernisation ?
Il croise le Renard. En l’apprivoisant, il développe l’empathie mécanique avec la technologie. La technologie bien employée peut lever des contraintes et atteindre de nouveaux possibles. Il découvre aussi que sa Rose est unique : c’est la cible que le SI doit atteindre pour que l’organisation soit alignée sur sa mission. Là maintenant, il sait quoi faire pour moderniser le SI !
On s’assoit sur une dune de sable. On ne voit rien. On n’entend rien. Et cependant quelque chose rayonne en silence…
L’Aviateur
Il lui reste à rentrer à la maison. Le Serpent vient à son aide. Pour que le SI revive, il doit abandonner sa vieille écorce corporelle.
Ce sera comme une vieille écorce abandonnée. Ce n’est pas triste les vieilles écorces…
Le Petit Prince
Le Petit Prince rejoint alors les étoiles et retrouve sa rose…
Comment savoir si son SI est vraiment modulaire ? Souvent, on le croit à tort.
Cet article explique les points à considérer dans l’évaluation de la modularité de son SI.
La modularité compte parmi les propriétés importantes d’un système d’information, car elle facilite d’autres caractéristiques très appréciables :
L’évolutivité pour ajouter, supprimer, adapter ou remplacer une zone du SI de façon autonome, sans engager de changement radical sur l’ensemble du SI ou une grande partie (aussi connue comme refonte ou big bang)
La modernisation – ou le traitement de l’obsolescence – pour remettre une zone du SI en conformité avec les exigences de maintien en condition opérationnelle indépendamment des autres zones.
Beaucoup de systèmes prétendent à être modulaire. Pourtant, ce n’est pas le cas en pratique. La raison est que l’on confond modularité avec découpage, classement ou encore cartographie. Être en mesure de ranger les applications dans des zones, quartiers ou îlots ne suffit pas à garantir la modularité.
Modularité versus Découpage
La raison vient que les processus se croisent dans le plan applicatif (généralement la chaine de valeur est orthogonale à l’organisation des fonctions de l’entreprise) et de là nait un entremêlement qui va naturellement contre la modularité. La modularité n’est donc pas automatique et dépend d’un travail conscient de conception.
La traversée des applications par les processus se traduit par des flux. La modularité vient donc des caractéristiques issues de ces flux :
Au niveau unitaire, la qualité du contrat de service, définissant les attendus et les contraintes applicables au flux
Au niveau global, le niveau d’acyclicité dans le graphe des flux, c’est-à-dire la densité des dépendances circulaires.
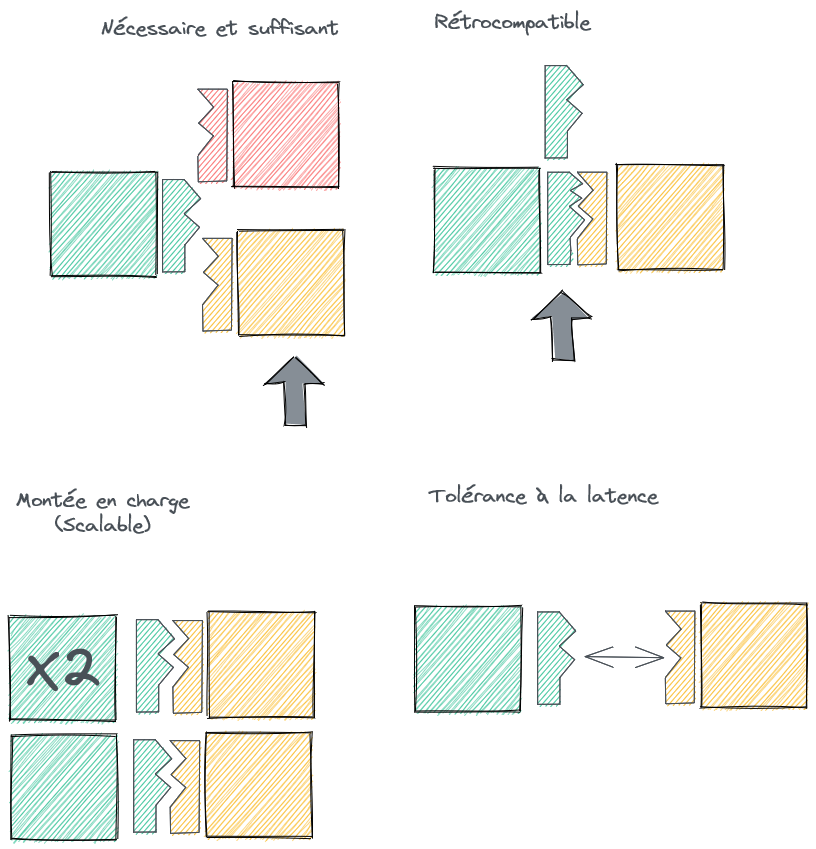
Le bon contrat de service (MaRTiN)
Le flux contribue à la modularité du SI s’il répond à un contrat de service qui a de bonnes propriétés :
Montée en charge (ou scalabilité) : le consommateur peut demander un accroissement du débit du flux à condition de respecter le capacity planning du producteur.
Rétrocompatibilité : le consommateur du flux peut converser avec le producteur dans une version plus ancienne.
Tolérance à la latence : la communication entre le producteur du flux et le consommateur du flux peut se faire avec des conditions larges de synchronicité (voir se faire en asynchrone).
Nécessaire et suffisant : les données échangées sont nécessaires pour répondre au cas d’usage sans dévoiler plus que nécessaire l’encapsulation du producteur.
Un moyen mnémotechnique est de se demander si notre contrat de service est bien MaRTiN !
Le contrat de service MaRTiN
On peut se convaincre que ces propriétés sont bien utiles :
La montée en charge est nécessaire pour supporter un cas d’usage qui s’ajoute ou se développe.
La rétrocompatibilité permet de faire évoluer un composant sans propager les changements.
La tolérance à la latence permet de localiser un composant plus ou moins près d’un autre avec qui il communique. On pourra penser aux contraintes posées par le Cloud hybride, l’Edge, …
Enfin, la dernière propriété demande un effort particulier de conception : assez pour transmettre la charge utile d’information, pas trop pour ne pas compromettre l’encapsulation des applications.
Idéalement, les applications communiquent au travers de bons contrats de service. Hélas, ce n’est qu’un idéal. Il n’y a pas d’alignement d’intérêt entre les éditeurs d’applications et les intégrateurs d’applications : les premiers recherchent la valeur ajoutée fonctionnelle quand les seconds s’intéressent à la continuité du SI. Quand le SI est le produit d’un patchwork de logiciels, il n’y a donc pas de raison particulière que les flux suivent de bons contrats.
Casser les contrats pour faire évoluer le SI
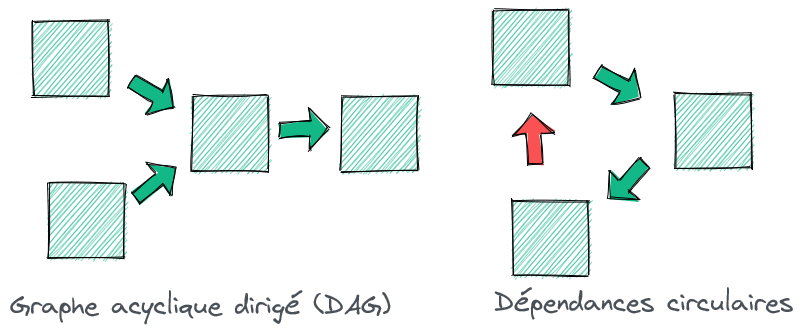
Dans un monde concret, les contrats doivent être cassés pour permettre l’évolution du SI. Tout n’est pas perdu ! Si les flux respectent l’acyclicité, il est alors possible de casser les contrats sans déstabiliser le SI. On pourrait parler de modularité faible. Il est temps d’aborder la seconde caractéristique utile des flux : l’acyclicité.
Les flux correspondent à des flots de données allant des producteurs vers les consommateurs. Quand les flux vont dans le même sens, il est alors possible de casser les contrats dans le même ordre et d’avoir un SI cohérent à chaque étape. À l’inverse, quand les flux refluent et forment des cycles, casser le contrat amène au dilemme suivant : mettre à jour l’ensemble du cycle (et faire une opération généralement crainte de bonne raison, le big bang) ou accepter d’avoir un SI instable pendant une certaine période de temps. Les flux peuvent être organisées selon un Graphe Acyclique Dirigé (Directed Acyclic Graph, DAG), un graphe complet ou une situation intermédiaire entre ces deux cas extrêmes avec plus ou moins de dépendances circulaires.
Organisation des flux
Un moyen pour pouvoir évaluer la situation courante est de faire une analyse DSM (Dependency Structure Matrix) en considérant les flux de données entre les nœuds applicatifs. Les flux sont rangés dans une matrice. L’algorithme DSM vise à arranger l’ordre des nœuds applicatifs pour rendre la matrice aussi triangulaire que possible. Si elle est triangulaire, bravo, il n’y a pas de dépendance circulaire. Vous avez même deux enchainements possibles pour remanier le SI tout en ayant des étapes intermédiaires stables. À l’inverse, si la matrice est remplie, le SI est analogue à un sac de nœud (ou un big ball of mud, comme disent nos amis anglo-saxons).
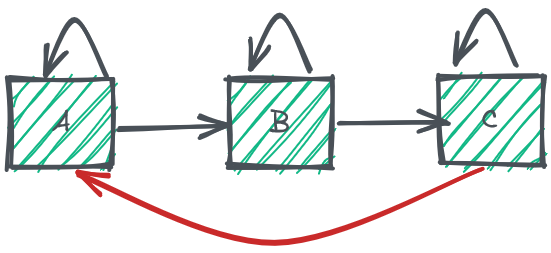
Pour se convaincre de l’analogie entre la triangularisation de la matrice DSM et de l’absence de dépendance circulaire, prenons l’exemple suivant : l’application A envoie un flux vers l’application B ; B envoie un flux vers C et C renvoie un flux vers A. Toutes les applications émettent un flux vers elles-mêmes, naturellement. On constate un cycle de dépendance.
Un exemple de graphe de dépendance
Maintenant, traduisons ce graphe dans une matrice de dépendance. On constate qu’on ne peut pas la triangulariser, c’est-à-dire faire que toutes les cases cochées soient au-dessus ou en dessous de la diagonale de la matrice. Si on casse le contrat de A vers B, alors l’impact concerne A, B, mais aussi C et doit être instruit simultanément pour maintenir la cohérence de l’ensemble.
Matrice DSM
Les surfaces des contrats de services sont plus grandes qu’on ne le pense.
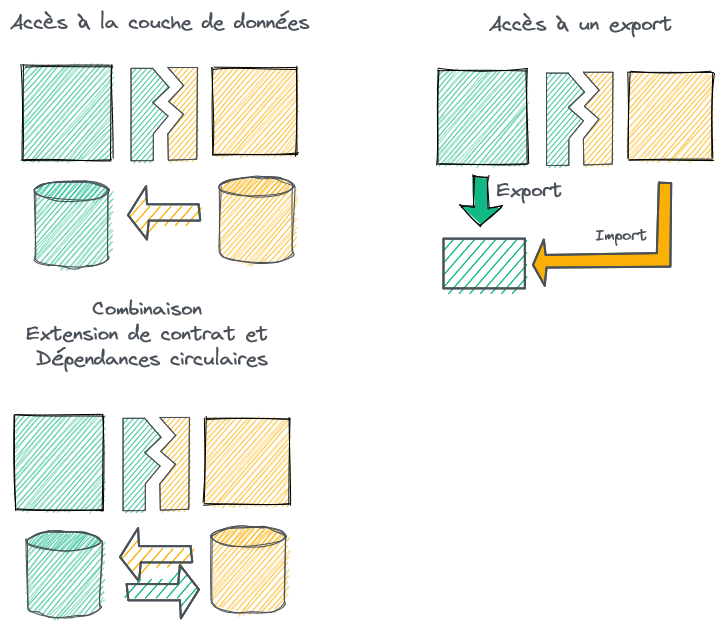
Les surfaces de contact entre les applications sont souvent plus grandes qu’on ne le pense. C’est aussi une des raisons dans mon expérience qui explique le décalage entre la perception des acteurs sur la modularité de leur SI et la réalité. Il arrive que les accès aux données puissent se faire en dehors de la couche de service. Par exemple, une application tierce peut avoir un accès direct sur la base de donnée, rendant caduque son encapsulation au passage. Un cas plus subtil est quand l’application exporte sa base de données dans un lac de données, son contrat de service s’étend de facto au schéma de la base de données. Nous pouvons un cas combiné de surface large et de dépendance circulaire quand les applications ont un accès aux autres bases de données. Cette situation, très défavorable, n’est malheureusement pas rare. Elle s’explique souvent par une stratégie opportuniste dans la durée.
Extensions de surface de contrat non désirées !
Conclusion
La modularité du SI est le produit de la qualité des contrats de service et de l’organisation des flux dans le SI. Elle dépend d’un travail soutenu de conception (et d’architecture !).
La modularité n’est jamais acquise : elle est fréquemment la première victime de l’entropie du SI. Bien souvent, la dégradation de la modularité se fait sans la prise de conscience des acteurs. À plusieurs reprises, j’ai vu des responsables être effarées par le sac de nœuds derrière un SI pourtant bien ordonné d’un point de vue externe : l’acceptation passe alors par les phases du deuil.
Accessoirement, l’analyse de la modularité d’un SI est le seul cas d’usage où j’ai fait appel à l’algèbre dans mes activités d’architecte. Rien que pour ça, cela méritait de s’y pencher !
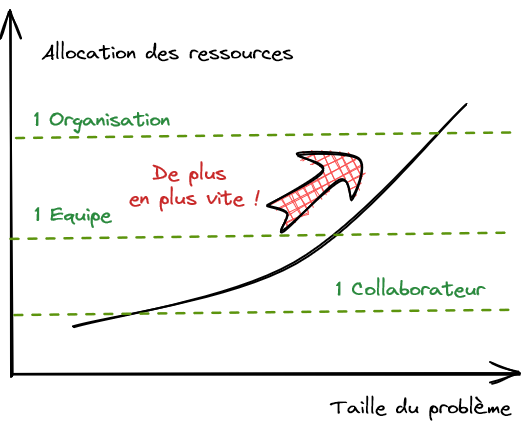
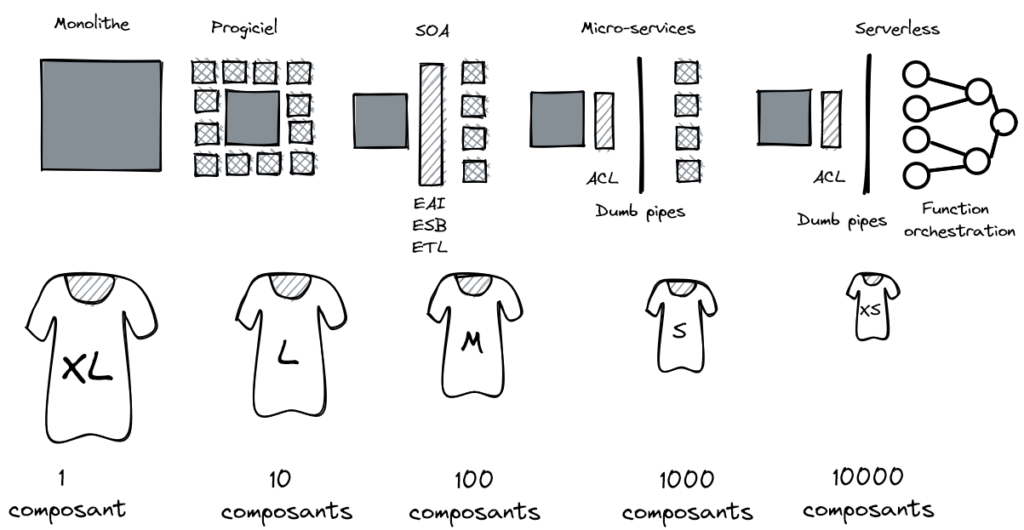
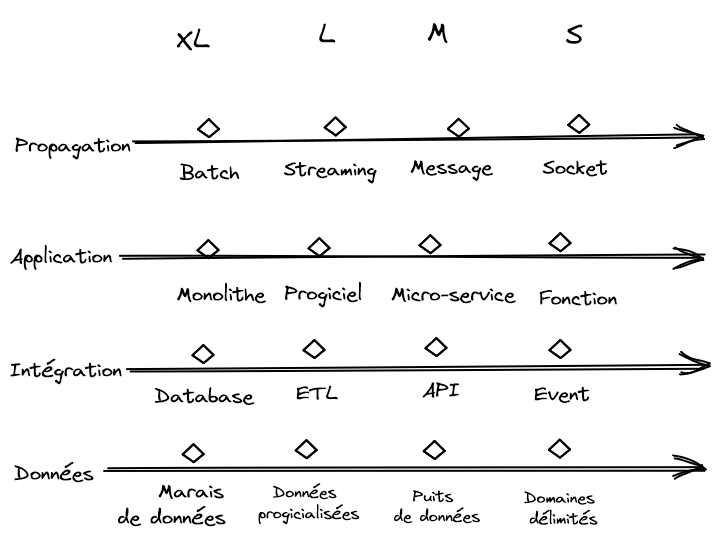
Le système d’information doit s’adapter de plus en plus vite pour répondre à la stratégie de l’entreprise. Nous sommes dans un contexte de plus en plus mouvant et de moins en moins prédictible, que l’on peut décrire sous l’acronyme VUCA : il faut donc évoluer en permanence sous peine d’être lâché. Comment aller plus vite dans un contexte économique poussant à la gestion parcimonieuse des ressources ? La réponse tient dans la taille. Et ici, être petit est un avantage !
La taille est un problème
L’allocation des ressources croît de façon non linéaire avec la dimension du problème. Si on considère une courbe avec les ressources en ordonnées et la taille du problème, on constate son accélération. Certes, une telle courbe est difficile à tracer avec précision en pratique ! Cette accélération est modélisée dans les méthodes de chiffrage classiques comme CoCoMo (I et II), ou encore dans la méthode des points de fonction. Cette accélération est également constatée en pratique : les gros projets demandent beaucoup plus de ressources, adressent des difficultés inhabituelles et ont des atterrissages souvent difficiles. Ce phénomène ne manque pas de surprendre à chaque fois ! On peut peut-être l’expliquer par le franchissement de seuils liés à la capacité cognitive d’un individu (1 ETP), la capacité de coordination d’une équipe (7 ETP) ou encore la capacité de gouvernance d’une organisation (50 ETP et plus) (voir le nombre de Dunbar). Par leur nature cognitive, ces effets de seuil nous sont difficiles à appréhender.
Une ressource se paie ! (PAID)
La ressource s’entend de façon large. On a d’abord le coût, le délai et la qualité (et avec la fonctionnalité qui est l’expression du besoin, on boucle le carré CQFD), au niveau de la gestion de projet. Au niveau informatique, cela se traduit par la granularité des traitements applicatifs (A), le découpage des modèles métier de données (D), l’intégration des traitements (I) et la propagation de l’information (P). Pour la suite, on pourra se rappeler ces 4 axes sous l’acronyme PAID. Une ressource se paie !
Les ressources PAID
Pas de taille unique
Pour être adaptable et rapide, il faut viser plus la taille S que la taille XL. Mais, la taille S a un coût et amène de la complexité globale. Aussi, le réglage entre la taille XL et la taille S dépend du contexte (une expression favorite des architectes !) :
Le besoin fonctionnel : En a-t-on vraiment besoin ? Faire simple, c’est déjà très bien. #KISS.
La maturité de la technologie et son accessibilité : Sait-on le faire bien ? Et si oui, à quel coût ? Les compétences nécessaires à la mise en œuvre sont-elles faciles à acquérir ou abondantes ?
L’importance stratégique : Doit-on mobiliser les moyens ? Où nous situons-nous dans une carte de Wardley ?
La question revient généralement : Est-ce que le gain de vitesse vaut au final la peine ? Avons-nous les moyens de nos ambitions ? Mais aussi, avons-nous vraiment le choix ?
Passer de taille en taille
Pour aller de la taille XL à la taille S, il ne faut pas négliger le passage par les tailles intermédiaires. À sauter les étapes, on risque de tomber dans l’imitation et le Cargo Cult alors qu’il est nécessaire de bien comprendre les avantages, mais aussi les contraintes qu’à chaque taille. De plus, chaque taille a une zone d’usage intemporelle, c’est-à-dire qu’elle répond à une classe de problèmes qui ont existé, existent et continueront probablement à exister.
On peut positionner le curseur sur chaque axe PAID avec une certaine liberté. Néanmoins, il y a une logique qui fait que, si on considère les axes PAID, les tailles de T-Shirt seront identiques à une taille près.
Cette logique s’applique domaine par domaine. Les domaines génériques seront plus dans les tailles XL ou L tandis que les domaines stratégiques ou cœur de métier utiliseront des tailles M ou S. Pour la qualification des domaines, on pourra s’appuyer sur une pratique comme le Core Domain Chart.
De XL à XS, parcours des axes PAID
Propagation
Déplacer beaucoup de donnée en suivant un calendrier ou avoir un flot de donnée quasiment continu s’avère être un compromis entre l’efficience technique et la fraîcheur de la donnée. La lecture séquentielle et la faible consommation réseau font des fichiers (ou des « objets » dans les objects storages) une solution très efficace pour transmettre les données. En revanche, elle impose des délais dans l’actualisation des données. La colocalisation des données dans un même fichier crée une adhérence artificielle entre ces données : généralement, on commence par lire le fichier par le début ! Le traitement des rejets doit-il se faire globalement ou unitairement ? À l’autre extrémité, on a des tuyaux de communication (sockets, WebSocket, connexions permanentes dans HTTP/3 avec QUIC) maintenus ouverts permettant le passage de petits messages en quasi-temps-réel et la parallélisation des traitements, certes avec une utilisation importante des ressources techniques.
Existe-t-il une taille de T-Shirt un peu extensible ? Oui ! Sur cet axe, comme sur les suivants, on peut identifier une solution Jack-all-of-trades capable de s’adapter à une large zone d’usage : il s’agit du streaming (ex : Apache Kafka) permettant un passage progressif entre le fichier et le message. Ces solutions Jack-all-of-trades sont précieuses dans la stratégie technologique, car elles permettent de faire évoluer la maturité du SI, domaine par domaine, sans chambouler le socle technologique.
Les tailles T-Shirt de l’axe Propagation
Application
Une application monolithique a un pouvoir d’intégration très fort : il est facile d’ajouter ou d’enrichir une fonction. Elle peut garder son évolution si elle est bien modulaire ou alors se faire ronger par l’entropie… jusqu’à devenir un big ball of mud. À l’autre bout du spectre, on peut avoir des modules applicatifs très fins, réduit potentiellement à la taille de fonction. Ce modèle de construction logicielle permet facilement l’ajout et l’extension des fonctionnalités (ou des features), certes au pris d’une intégration plus complexe et plus fragile en raison de la nature incertaine du réseau. Au passage, on pourrait penser que cette approche garantit la modularité. Malheureusement, cette modularité n’est pas toujours automatique : si les micro-services ou les fonctions n’ont pas des contrats d’interface stables, il devient impossible de mener un changement sans régression et on se retrouve devant… un distributed big ball of mud.
Notre solution Jack-all-of-trades est ici le dumb pipe. Le « tuyau stupide » fournit une intégration robuste et prédictible entre les applications, qu’elles soient un progiciel, une application, un micro-service ou une fonction. Si en plus les applications productrices, celles qui sont en amont des tuyaux stupides, peuvent exposer des interfaces normalisées (ou API) et utiliser des formats unifiés (ou modèle pivot), alors on peut réduire fortement le nombre de tuyaux (on descend radicalement la complexité qui de O(n²) passe en O(n) !). Tout n’est pas simple, car il faut faire parler les applications à travers les tuyaux stupides : c’est là que connecteurs, micro-services rentrent dans la dance pour combler les écarts.
Les tailles T-Shirt de l’axe Application
Intégration
L’intégration entre deux traitements du SI se qualifie par la surface de contact et par la force du contrat régissant ce contact. La surface peut être extrêmement large et le contrat très fort dans le cas de l’intégration par les données : le consommateur a accès à l’ensemble du modèle de donnée et le producteur lui garantit une rétrocompatibilité sur le schéma de la base. C’est un modèle favorable au consommateur. Il demande peu d’effort au producteur pour l’exposition, mais il ne favorise par l’évolutivité. De l’autre côté, on peut avoir un modèle de communication par événement, l’actor model. La surface est réduite à la charge de l’événement et le contrat se réduit au futur et potentiel traitement de l’événement. Le producteur est en charge d’émettre les événements tandis que le consommateur doit évoluer pour comprendre le contexte au travers des événements qu’il reçoit. Nous sommes dans une configuration nettement plus évolutive. Une approche de conception récente, intéressante et aussi radicale, reposant sur l’intégration par les événements est Event Modeling.
Notre solution jack-all-of-trades est ici l’API qui permet de poser un contrat sur un domaine métier délimité plus ou moins large. La granularité de l’API permet de remonter à la synchronisation de référentiel ou de descendre au niveau événementiel.
Les tailles T-Shirt de l’axe Intégration
Données
Le découpage des modèles métier peut aller d’un modèle métier sans rupture, le « marais des données », à une structure de domaines délimités (Bounded contexts) . Commencer par le « marais » n’est pas une mauvaise chose, mais finit par devenir intenable au fur et à mesure que les différents métiers mûrissent leur point de vue fonctionnel et tirent de plus en plus fort dans leur direction.
Le modèle intermédiaire basé sur la progicialisation se voit fréquemment. Le cœur du métier est adressé par un progiciel. Ce dernier, avec ses processus et son modèle métier, définit le point de vue. Afin de ne pas trop le « tordre », il est complété par des applications satellites. Jusque-là, tout va bien. La situation se complique quand on voit apparaître un second progiciel utilisé par un autre métier : quel progiciel va dominer ? Cette question est difficile à traiter sans la capacité de concevoir des formats pivot. Il est même possible qu’un progiciel, retiré du SI, continue à impacter le SI à travers la structure des flux qui, eux, sont encore là et le comble est quand le modèle métier de l’ancien progiciel s’impose au nouveau !
Sur cet axe, le jack-of-trades est le modèle de persistance. Entre le stockage en fichiers plats, peu intègre et souple, et le stockage relationnel, rigoureux, mais rigide, le stockage dans des bases orientées document (ex : MongoDB) fournisse un média très versatile qui permet d’ajuster le curseur entre structure et flexibilité, ce qui est idéal pour construire des formats pivots ou des structures d’échange.
Les tailles T-Shirt de l’axe Donnée
En conclusion
Les solutions dans le Système d’information se positionnent sur des axes décrivant des modèles d’implémentation caractérisés par une granularité de taille. Ce positionnement répond à un choix entre coût et vitesse, ou encore entre standard et différenciation. Il peut se faire de façon assez libre par axe et par domaine métier.
Les axes, au nombre de 4, représentent le modèle de propagation de la donnée (P), la granularité des applicatifs (A), le modèle d’intégration des applicatifs (I) et le découpage des modèles métiers (D). On peut se les rappeler par l’acronyme mnémotechnique PAID.
Le déplacement sur les axes doit se faire taille par taille. Chaque leçon demande du temps pour être réellement comprise.
La bonne nouvelle est qu’il existe des solutions polyvalentes qui facilitent le déplacement sur les axes : le streaming pour la propagation, les dumb pipes pour les applications, l’API pour l’intégration, le modèle documentairepour les données.