Le système d’information doit s’adapter de plus en plus vite pour répondre à la stratégie de l’entreprise. Nous sommes dans un contexte de plus en plus mouvant et de moins en moins prédictible, que l’on peut décrire sous l’acronyme VUCA : il faut donc évoluer en permanence sous peine d’être lâché. Comment aller plus vite dans un contexte économique poussant à la gestion parcimonieuse des ressources ? La réponse tient dans la taille. Et ici, être petit est un avantage !
La taille est un problème
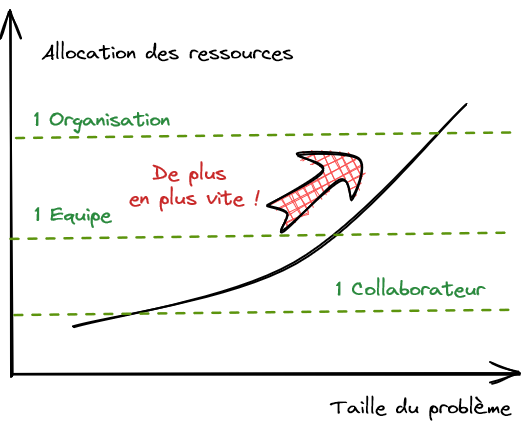
L’allocation des ressources croît de façon non linéaire avec la dimension du problème. Si on considère une courbe avec les ressources en ordonnées et la taille du problème, on constate son accélération. Certes, une telle courbe est difficile à tracer avec précision en pratique ! Cette accélération est modélisée dans les méthodes de chiffrage classiques comme CoCoMo (I et II), ou encore dans la méthode des points de fonction. Cette accélération est également constatée en pratique : les gros projets demandent beaucoup plus de ressources, adressent des difficultés inhabituelles et ont des atterrissages souvent difficiles. Ce phénomène ne manque pas de surprendre à chaque fois ! On peut peut-être l’expliquer par le franchissement de seuils liés à la capacité cognitive d’un individu (1 ETP), la capacité de coordination d’une équipe (7 ETP) ou encore la capacité de gouvernance d’une organisation (50 ETP et plus) (voir le nombre de Dunbar). Par leur nature cognitive, ces effets de seuil nous sont difficiles à appréhender.
Une ressource se paie ! (PAID)
La ressource s’entend de façon large. On a d’abord le coût, le délai et la qualité (et avec la fonctionnalité qui est l’expression du besoin, on boucle le carré CQFD), au niveau de la gestion de projet. Au niveau informatique, cela se traduit par la granularité des traitements applicatifs (A), le découpage des modèles métier de données (D), l’intégration des traitements (I) et la propagation de l’information (P). Pour la suite, on pourra se rappeler ces 4 axes sous l’acronyme PAID. Une ressource se paie !
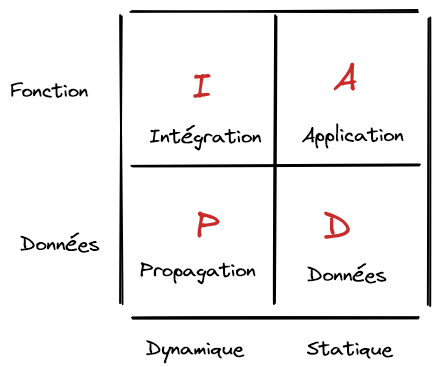
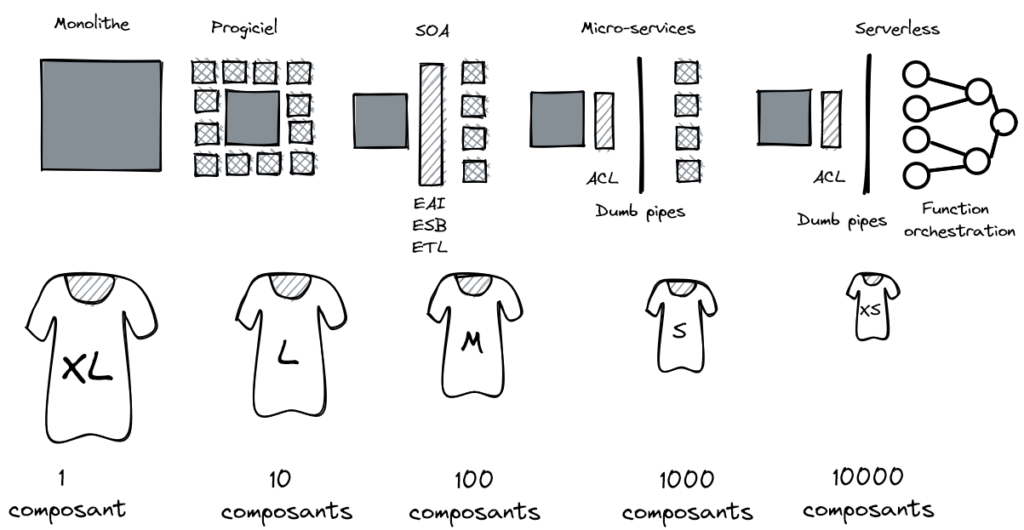
Pas de taille unique
Pour être adaptable et rapide, il faut viser plus la taille S que la taille XL. Mais, la taille S a un coût et amène de la complexité globale. Aussi, le réglage entre la taille XL et la taille S dépend du contexte (une expression favorite des architectes !) :
- Le besoin fonctionnel : En a-t-on vraiment besoin ? Faire simple, c’est déjà très bien. #KISS.
- La maturité de la technologie et son accessibilité : Sait-on le faire bien ? Et si oui, à quel coût ? Les compétences nécessaires à la mise en œuvre sont-elles faciles à acquérir ou abondantes ?
- L’importance stratégique : Doit-on mobiliser les moyens ? Où nous situons-nous dans une carte de Wardley ?
La question revient généralement : Est-ce que le gain de vitesse vaut au final la peine ? Avons-nous les moyens de nos ambitions ? Mais aussi, avons-nous vraiment le choix ?
Passer de taille en taille
Pour aller de la taille XL à la taille S, il ne faut pas négliger le passage par les tailles intermédiaires. À sauter les étapes, on risque de tomber dans l’imitation et le Cargo Cult alors qu’il est nécessaire de bien comprendre les avantages, mais aussi les contraintes qu’à chaque taille. De plus, chaque taille a une zone d’usage intemporelle, c’est-à-dire qu’elle répond à une classe de problèmes qui ont existé, existent et continueront probablement à exister.
On peut positionner le curseur sur chaque axe PAID avec une certaine liberté. Néanmoins, il y a une logique qui fait que, si on considère les axes PAID, les tailles de T-Shirt seront identiques à une taille près.
Cette logique s’applique domaine par domaine. Les domaines génériques seront plus dans les tailles XL ou L tandis que les domaines stratégiques ou cœur de métier utiliseront des tailles M ou S. Pour la qualification des domaines, on pourra s’appuyer sur une pratique comme le Core Domain Chart.
De XL à XS, parcours des axes PAID
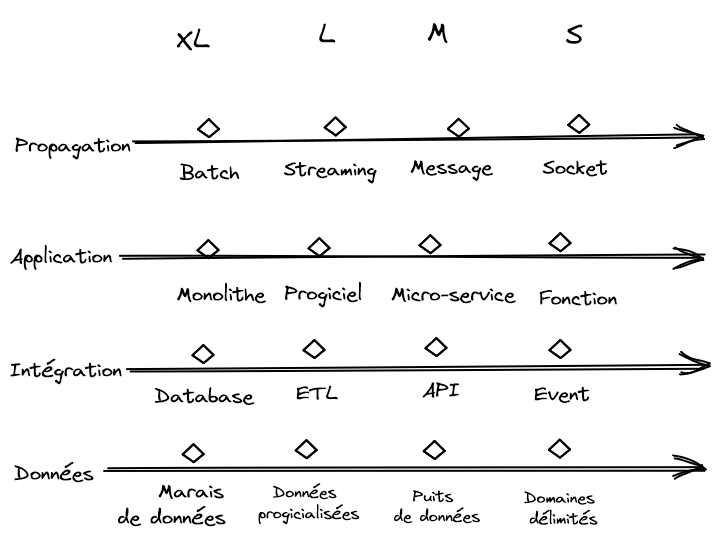
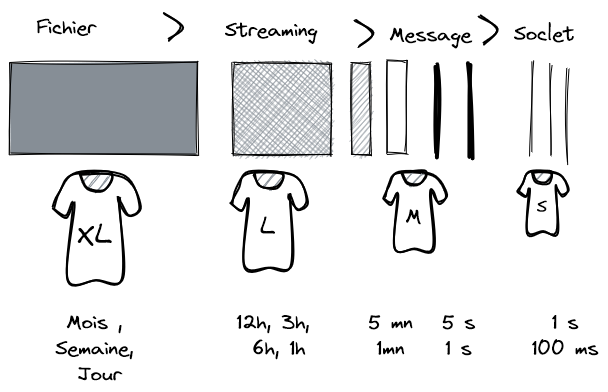
Propagation
Déplacer beaucoup de donnée en suivant un calendrier ou avoir un flot de donnée quasiment continu s’avère être un compromis entre l’efficience technique et la fraîcheur de la donnée. La lecture séquentielle et la faible consommation réseau font des fichiers (ou des « objets » dans les objects storages) une solution très efficace pour transmettre les données. En revanche, elle impose des délais dans l’actualisation des données. La colocalisation des données dans un même fichier crée une adhérence artificielle entre ces données : généralement, on commence par lire le fichier par le début ! Le traitement des rejets doit-il se faire globalement ou unitairement ? À l’autre extrémité, on a des tuyaux de communication (sockets, WebSocket, connexions permanentes dans HTTP/3 avec QUIC) maintenus ouverts permettant le passage de petits messages en quasi-temps-réel et la parallélisation des traitements, certes avec une utilisation importante des ressources techniques.
Existe-t-il une taille de T-Shirt un peu extensible ? Oui ! Sur cet axe, comme sur les suivants, on peut identifier une solution Jack-all-of-trades capable de s’adapter à une large zone d’usage : il s’agit du streaming (ex : Apache Kafka) permettant un passage progressif entre le fichier et le message. Ces solutions Jack-all-of-trades sont précieuses dans la stratégie technologique, car elles permettent de faire évoluer la maturité du SI, domaine par domaine, sans chambouler le socle technologique.
Application
Une application monolithique a un pouvoir d’intégration très fort : il est facile d’ajouter ou d’enrichir une fonction. Elle peut garder son évolution si elle est bien modulaire ou alors se faire ronger par l’entropie… jusqu’à devenir un big ball of mud. À l’autre bout du spectre, on peut avoir des modules applicatifs très fins, réduit potentiellement à la taille de fonction. Ce modèle de construction logicielle permet facilement l’ajout et l’extension des fonctionnalités (ou des features), certes au pris d’une intégration plus complexe et plus fragile en raison de la nature incertaine du réseau. Au passage, on pourrait penser que cette approche garantit la modularité. Malheureusement, cette modularité n’est pas toujours automatique : si les micro-services ou les fonctions n’ont pas des contrats d’interface stables, il devient impossible de mener un changement sans régression et on se retrouve devant… un distributed big ball of mud.
Notre solution Jack-all-of-trades est ici le dumb pipe. Le « tuyau stupide » fournit une intégration robuste et prédictible entre les applications, qu’elles soient un progiciel, une application, un micro-service ou une fonction. Si en plus les applications productrices, celles qui sont en amont des tuyaux stupides, peuvent exposer des interfaces normalisées (ou API) et utiliser des formats unifiés (ou modèle pivot), alors on peut réduire fortement le nombre de tuyaux (on descend radicalement la complexité qui de O(n²) passe en O(n) !). Tout n’est pas simple, car il faut faire parler les applications à travers les tuyaux stupides : c’est là que connecteurs, micro-services rentrent dans la dance pour combler les écarts.
Intégration
L’intégration entre deux traitements du SI se qualifie par la surface de contact et par la force du contrat régissant ce contact. La surface peut être extrêmement large et le contrat très fort dans le cas de l’intégration par les données : le consommateur a accès à l’ensemble du modèle de donnée et le producteur lui garantit une rétrocompatibilité sur le schéma de la base. C’est un modèle favorable au consommateur. Il demande peu d’effort au producteur pour l’exposition, mais il ne favorise par l’évolutivité. De l’autre côté, on peut avoir un modèle de communication par événement, l’actor model. La surface est réduite à la charge de l’événement et le contrat se réduit au futur et potentiel traitement de l’événement. Le producteur est en charge d’émettre les événements tandis que le consommateur doit évoluer pour comprendre le contexte au travers des événements qu’il reçoit. Nous sommes dans une configuration nettement plus évolutive. Une approche de conception récente, intéressante et aussi radicale, reposant sur l’intégration par les événements est Event Modeling.
Notre solution jack-all-of-trades est ici l’API qui permet de poser un contrat sur un domaine métier délimité plus ou moins large. La granularité de l’API permet de remonter à la synchronisation de référentiel ou de descendre au niveau événementiel.

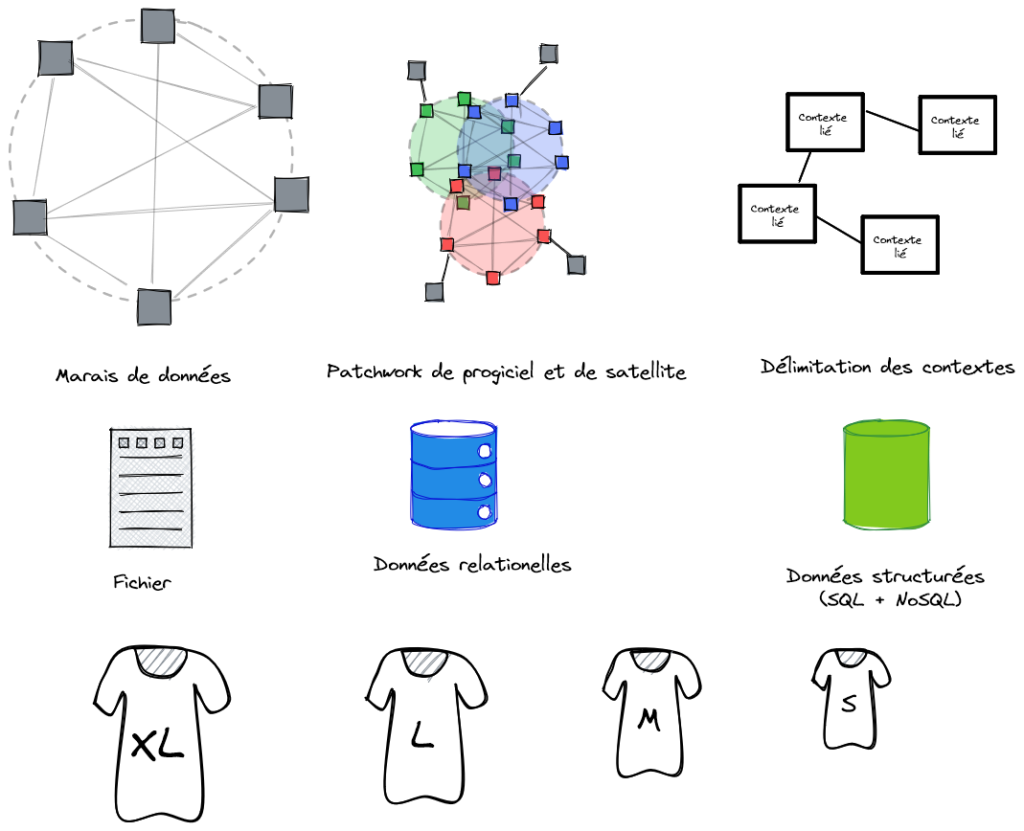
Données
Le découpage des modèles métier peut aller d’un modèle métier sans rupture, le « marais des données », à une structure de domaines délimités (Bounded contexts) . Commencer par le « marais » n’est pas une mauvaise chose, mais finit par devenir intenable au fur et à mesure que les différents métiers mûrissent leur point de vue fonctionnel et tirent de plus en plus fort dans leur direction.
Le modèle intermédiaire basé sur la progicialisation se voit fréquemment. Le cœur du métier est adressé par un progiciel. Ce dernier, avec ses processus et son modèle métier, définit le point de vue. Afin de ne pas trop le « tordre », il est complété par des applications satellites. Jusque-là, tout va bien. La situation se complique quand on voit apparaître un second progiciel utilisé par un autre métier : quel progiciel va dominer ? Cette question est difficile à traiter sans la capacité de concevoir des formats pivot. Il est même possible qu’un progiciel, retiré du SI, continue à impacter le SI à travers la structure des flux qui, eux, sont encore là et le comble est quand le modèle métier de l’ancien progiciel s’impose au nouveau !
Sur cet axe, le jack-of-trades est le modèle de persistance. Entre le stockage en fichiers plats, peu intègre et souple, et le stockage relationnel, rigoureux, mais rigide, le stockage dans des bases orientées document (ex : MongoDB) fournisse un média très versatile qui permet d’ajuster le curseur entre structure et flexibilité, ce qui est idéal pour construire des formats pivots ou des structures d’échange.
En conclusion
Les solutions dans le Système d’information se positionnent sur des axes décrivant des modèles d’implémentation caractérisés par une granularité de taille. Ce positionnement répond à un choix entre coût et vitesse, ou encore entre standard et différenciation. Il peut se faire de façon assez libre par axe et par domaine métier.
Les axes, au nombre de 4, représentent le modèle de propagation de la donnée (P), la granularité des applicatifs (A), le modèle d’intégration des applicatifs (I) et le découpage des modèles métiers (D). On peut se les rappeler par l’acronyme mnémotechnique PAID.
Le déplacement sur les axes doit se faire taille par taille. Chaque leçon demande du temps pour être réellement comprise.
La bonne nouvelle est qu’il existe des solutions polyvalentes qui facilitent le déplacement sur les axes : le streaming pour la propagation, les dumb pipes pour les applications, l’API pour l’intégration, le modèle documentaire pour les données.